Non-Redundant / Simplex Mode Deployment
In a single server deployment, the application is installed on the same server with a single point of failure.
High Availability (HA) / Duplex Deployment
Database failover with MS SQL
A two-node SQL Server is required to be setup in a failover cluster mode. ExpertFlow applications will connect to the MS SQL Server cluster via a SQL user to create application database schema. The cluster should be accessible through the unique SQL Server cluster VIP (Virtual IP).
ExpertFlow requires a SQL user with the database role db_owner on each of EF application’s database.
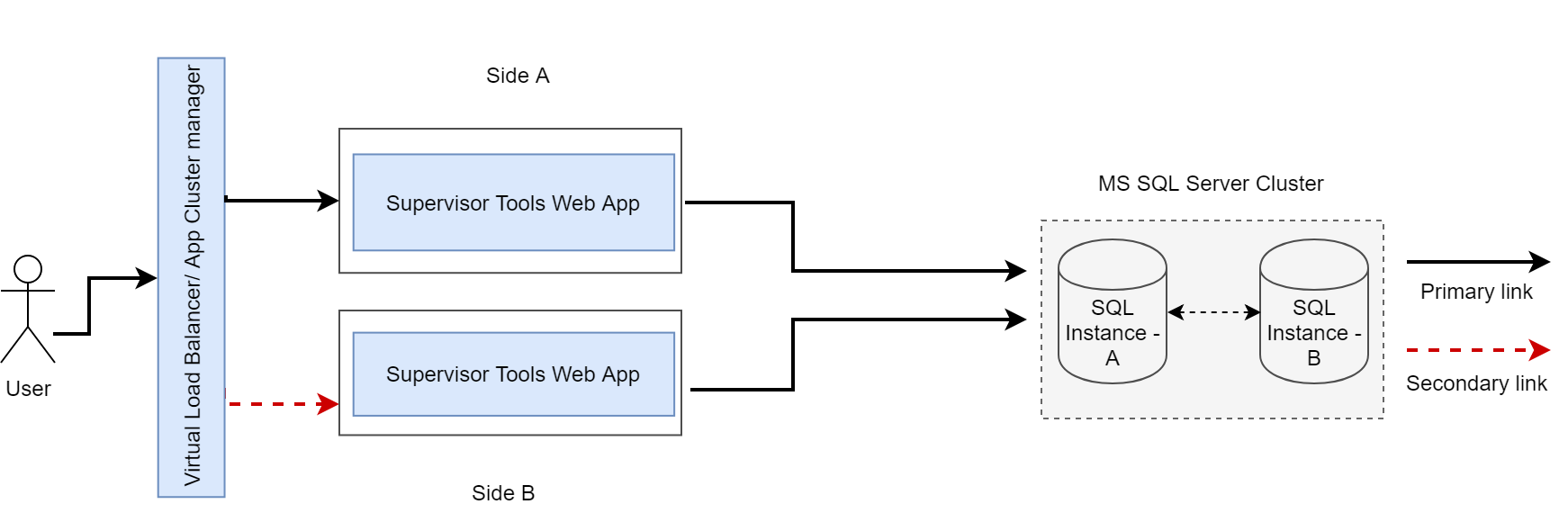
High Availability with MS SQL Server
Application failover
All EF applications are deployed on a two-nodes cluster/ VMs with one node being the Primary and the other being the secondary to provide fault tolerance and high availability of the applications. Both of the two nodes will have everything running on the machines, thus, acting as a replica of each other. Each node of the cluster exposes a VIP (Virtual IP, using VRR protocol) which will route service request to the active primary node at any point in time.
The two nodes will be synchronized with KeepAlived enabled such that as soon the primary node becomes down, the secondary node resumes services and acts as primary. Thus, the failover from primary to secondary happens nearly seamlessly.
The overall architecture will look like below.

Each Node represents a VM.
For the hardware resilience, these nodes/VMs should be on two physical servers. If all the VMs are deployed on the same physical server, it will provide only VM level resilience and fault tolerance.
Failover scenarios
|
When the Primary or Secondary node is down |
|||||||
|
The system will switch to the other active node. |
|||||||
|
Impact |
All applications will continue to work after the seamless failover. |
||||||
|
Recovery |
NA |
||||||
|
When Primary and Secondary nodes are down |
|||||||
|
Impact |
All applications and services will not work. |
||||||
|
Recovery |
The manual intervention is required to recover the system. |
||||||
|
When primary or secondary SupervisorTools instance is down |
|||||||
|
The other active instance will make itself primary as it becomes aware of the failure of the primary node using KeepAlived |
|||||||
|
Impact |
All read/write operations on the Supervisor Tools will continue to function seamlessly. No impact on live calls. With MSSQL Server failover cluster, there’ll be no loss of data. |
||||||
|
Recovery |
For any integration between the IVR and the web app, the Supervisor Tools APIs used in the IVR scripts will seamlessly failover to the secondary instance to provide the appropriate call treatment. The failover for the web users will also be seamless with a virtual web portal IP. |
||||||
|
When primary and secondary Supervisor Tools instances are down |
|||||||
|
Impact |
All read/write operations on the datastore will fail. |
||||||
|
Recovery |
A manual intervention is required to resume the datastore operations. |
||||||