Conversation Orchestration
-
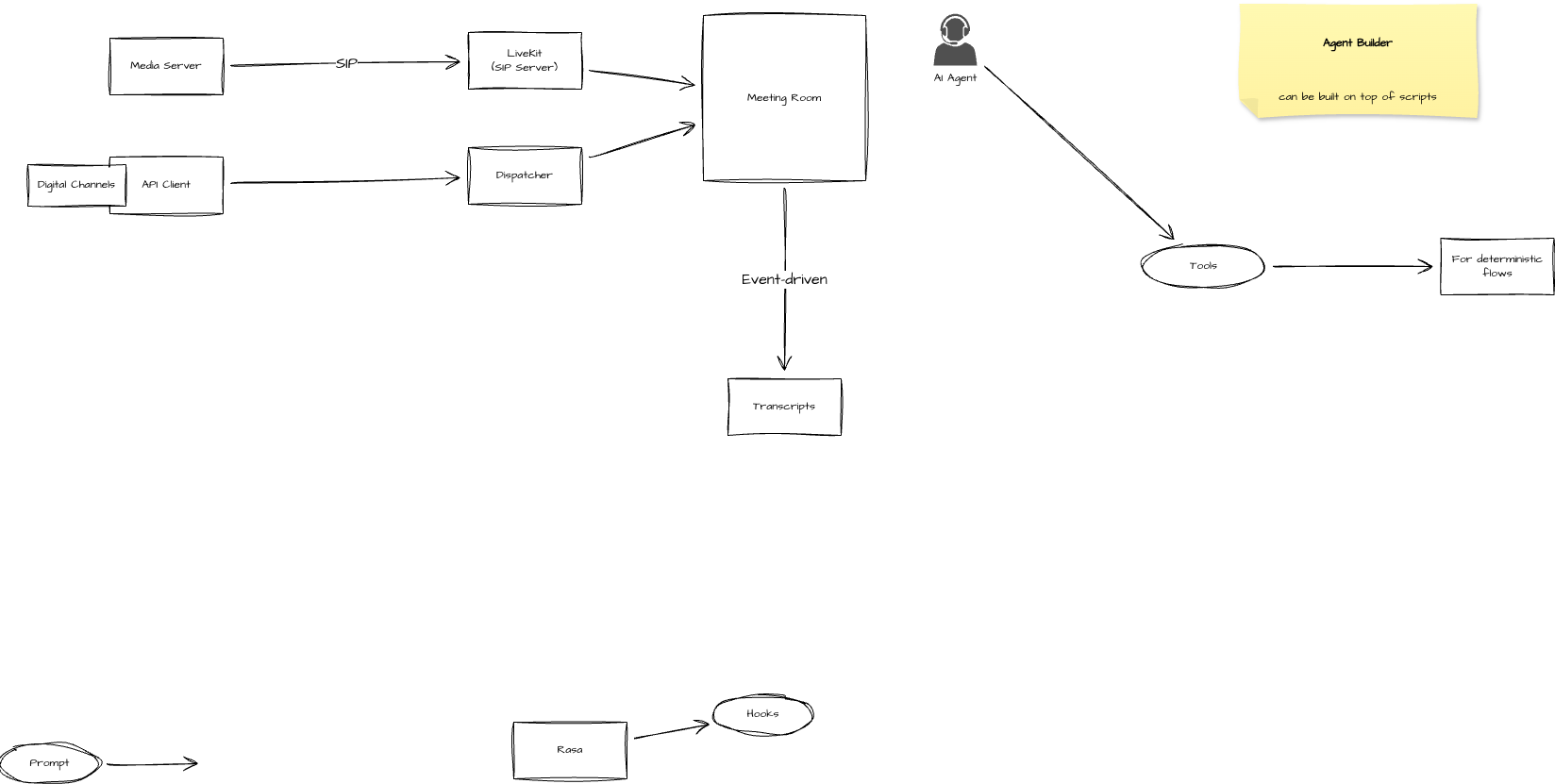
Orchestration of inbound/outbound conversation across all channels with hand-off to multiple AI-agents or may be human agents through the conversation flow with support of deterministic rule-based logical flows as well.
-
Flow of a conversation triggered by something (customer sent a message, voice call, etc) → Flow Builder
-
Invoke agents within the flow
-
These agents are created somewhere separately in some Agent Builder.
-
-
-
Flow Builder allows creating multiple conversation flows.
How It Works: Division of Labor
1. The LLM (The Brain)
The LLM serves as the decision and reasoning core. It:
-
Interprets the user’s natural language input and determines intent.
-
Chooses the correct action pathway:
-
General Query: Uses a Retrieval-Augmented Generation (RAG) pipeline to fetch relevant knowledge from domain-specific documents and generate an accurate, grounded response.
-
Transactional Query: Invokes a BPMN-driven deterministic flow to execute predefined business processes such as order tracking, record updates, or account management.
-
-
Applies guardrails to prevent hallucinations, prompt injections, and unauthorized actions.
2. The Orchestrator (The Body)
The Orchestrator acts as the secure execution layer responsible for:
-
Tool & System Integration: Connecting the LLM to external services—AI engines (ASR/TTS), CRMs, ERPs, and APIs.
-
Workflow Management: Executing BPMN flows for structured processes.
-
Validation & Security Enforcement: Enforcing authentication, authorization, and data policies before any action.
-
Controlled Execution: Ensuring all API calls and data exchanges occur within a secure environment, mediated through the Orchestrator.
This division of labor allows the LLM to focus on reasoning while the Orchestrator ensures compliant, deterministic execution.
The Hybrid Model: Power Meets Compliance
To support enterprise and regulated environments, the system adopts a hybrid and engine-agnostic deployment model that offers both flexibility and compliance.
Engine Agnostic Design
The AI Orchestrator is designed to integrate with any LLM engine, whether open-source (e.g., Ollama, Llama 2, Mistral, Falcon, Mixtral) or commercial APIs (e.g., OpenAI GPT, Anthropic Claude, Google Gemini, Azure OpenAI Service).
This flexibility allows organizations to:
-
Choose their preferred model provider based on cost, performance, and data policies.
-
Seamlessly switch or combine engines without changing orchestration logic.
-
Leverage EF’s own LLM engine, built on open-source technology, for fully private and customizable deployments.
The Orchestrator remains engine-agnostic, meaning it communicates with any LLM through a standardized adapter layer that abstracts model-specific implementations.
Flexible Deployment Options
The system can be deployed both on-premise or in the cloud, depending on organizational requirements:
-
On-Premise / Private Cloud: For maximum control and compliance, all components—including the Orchestrator, BPMN engine, RAG index, and business APIs—run in a secure private infrastructure.
-
Public Cloud: For scalability and access to the latest AI models, organizations may choose to integrate cloud-hosted LLMs while keeping sensitive logic and data private.
This hybrid configuration ensures that reasoning can leverage the power of large-scale public LLMs, while execution, workflows, and data remain under enterprise control.
Data Privacy & Compliance
The Orchestrator enforces strict PII (Personally Identifiable Information) compliance via Microsoft Presidio Analyizer across all interactions:
-
No customer-specific or sensitive data is transmitted to public LLMs.
-
Prompts are contextually crafted and anonymized before being sent externally.
-
All execution logic, business data, and audit trails remain fully within the private environment.
This guarantees data sovereignty, regulatory compliance (e.g., GDPR, HIPAA), and customer trust—without compromising on AI capability.
Security & Guardrails
To ensure reliability and safety:
-
Prompt Injection Protection: Sanitizes inputs to prevent malicious prompt manipulation.
-
Context Filtering: Ensures only approved data fields are included in prompts.
-
Response Validation: All LLM outputs pass through a validation layer before execution.
-
Anti-Hallucination Measures: RAG grounding ensures factual accuracy, while BPMN flows guarantee deterministic actions.