Please note that this is an off-set interval data pipeline, means this pipeline will bring in data with an offset of 15 minutes. For example, if the pipeline is run on the date 17-06-2025 at time 12:30:00 the data that will be processed and inserted in the tables would be from the interval 12:00:00 to 12:15:00 of the same date.
Purpose:
-
For the gold queries that are dependent on multiple tables to execute and get gold level data in our target database, we needed to load all the silver layer data in our target database first and then execute the gold queries.
-
Previously, we used the main campaigns and activities pipeline with a single task for executing gold queries but this led to missing data because of dependencies between the pipeline data.
-
So, for this purpose we have completely removed that task from the main pipeline and made a separate consolidated DAG with a 15 minutes offset interval, to ensure no data is missed and valid data is inserted.
-
To run the pipeline and load please refer directly here: https://expertflow-docs.atlassian.net/wiki/spaces/CX/pages/1147404525/Campaigns+15+Minutes+Gold+Queries+Pipeline#How-to-Run-the-pipeline%3A
Overview:
In this new approach first all the data is loaded in the silver tables with our previous Campaigns and Activities pipeline and then a dedicated gold queries pipeline is run with an 15 minute offset to load gold layer data in the relevant database tables.
Gold Queries:
The following gold queries would be executed by this pipeline:
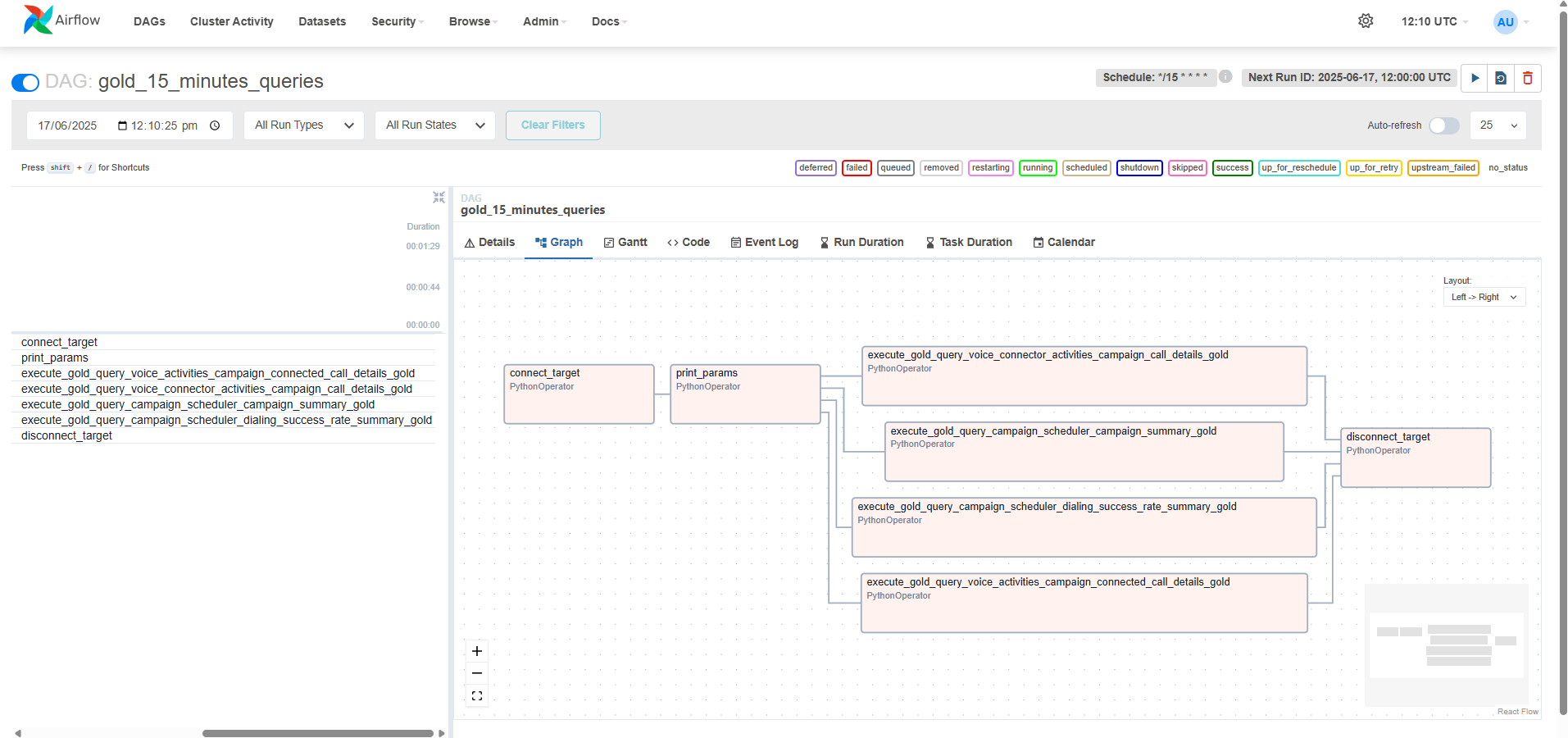
Configurations:
Configurations for Gold Queries Data Pipeline are provided in a yaml format in transflux/config directory in your solution deployment to ensure flexibility and adaptability. These configurations are designed for normal and ideal use cases and are advised to be used as-is to achieve optimal results.
pipelines:
voice_activities:
queries:
- campaign_connected_call_details_gold
voice_connector_activities:
queries:
- campaign_call_details_gold
campaign_scheduler:
queries:
- campaign_summary_gold
- dialing_success_rate_summary_gold
target:
type: "mysql"
db_url: "mysql+pymysql://<your-db-username>:<password>@<host>:<port>/<mysql-db-name>"
#db_url: "mssql+pyodbc://<your-db-username>:<password>@<host>:<port>/<mssql-db-name>?<driver_name>"
enable_ssl: false # Enable or disable SSL connections
ssl_ca: "/transflux/certificates/mysql_certs/ca.pem"
ssl_cert: "/transflux/certificates/mysql_certs/client-cert.pem"
ssl_key: "/transflux/certificates/mysql_certs/client-key.pem"
schedule_interval: "*/15 * * * *"
time_offset: "-15"
interval_minutes: 15
start_date: "2025-06-17T00:00:00+00:00" #Change date according to your data
catchup: true
How to Run the pipeline:
In order to run the gold queries and get data in the gold tables, there can be two cases.
1. If there is no Historical Data to be loaded:
For this case if you don't have any historical campaigns data, you can simply set the datetime within your accordance in start_date field in the configuration file and simply just un-pause the pipeline from the Data Platform UI to start executing the gold queries on your data.
2. If there is some Historical Data to be loaded:
In case you have Historical Data regarding campaigns then you would have trigger the pipeline manually from the Data Platform UI. Please follow the following steps for this purpose:
-
Go to your configuration file and set the datetime in
start_timeto the current datetime or the datetime from which you want to run your latest gold query data. After this un-pause the gold queries pipeline in Data Platform UI and the schedule will start executing the gold query on the data according to your setstart_timein the configuration file. -
Now for running the gold query on the historical data, go to your pipeline and select the trigger option in the top right corner of the Data Platform UI as shown below.
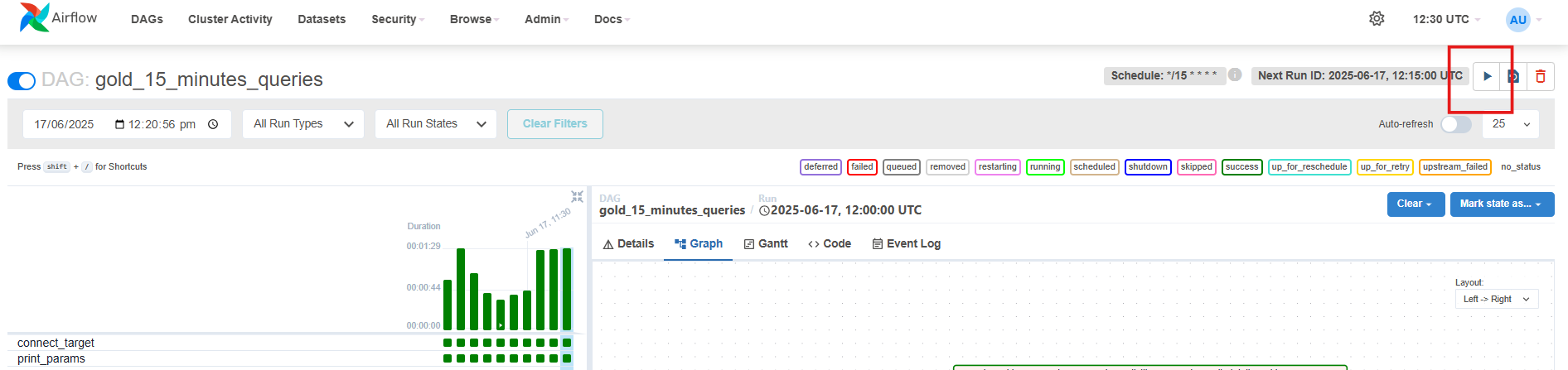
-
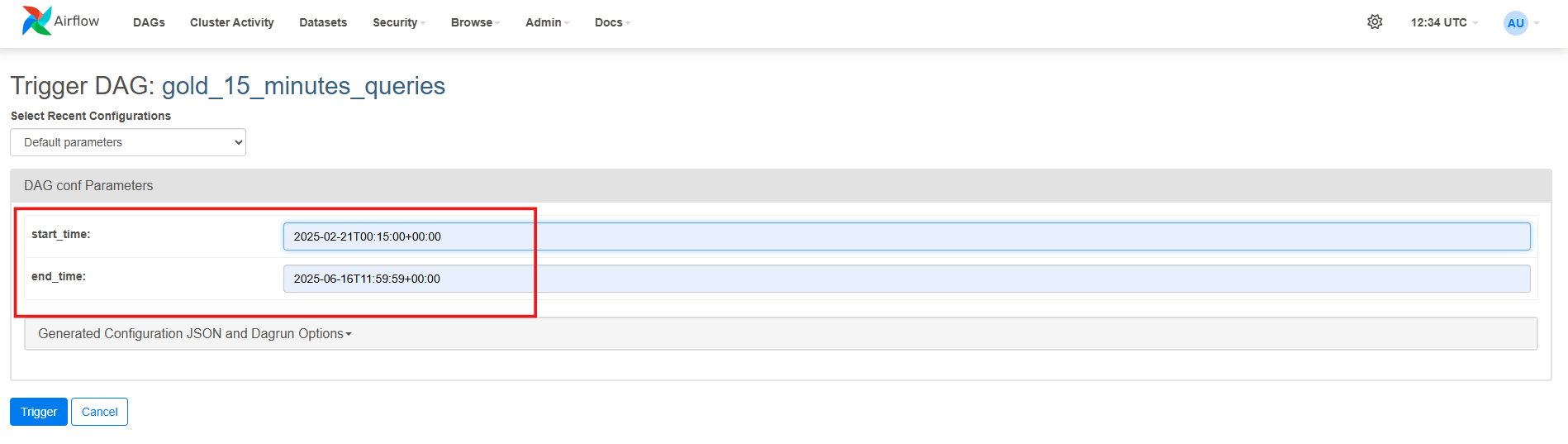
Once you click the trigger option you would be presented with the following screen. Enter the
start_timeandend_timewith the same format as being shown in the screenshot according to which your data is present (start_timebeing the oldest data andend_timebeing the latest data). In the case attached in the screenshot, the oldest data for campaigns was generated on date 21-02-2025 and the latest data present was for date 16-06-2025, so please check your MongoDB and check the datetime for latest and oldest data and add the dates here accordingly.
Please add the date and time carefully, ensuring no time interval is missed to get the complete data in your database. The time should be added here according to UTC timezone.
-
Once you set your dates here, click ‘Trigger’. This will start the pipeline run and will execute the gold queries on the historical data present according to the start and end datetime given in the configuration file and load all the historical gold level data in a single run.