This document provides comprehensive technical documentation for each Mysql ETL job for the EFCX system.
The same process has been replicated for MSSQL ETL jobs as well.
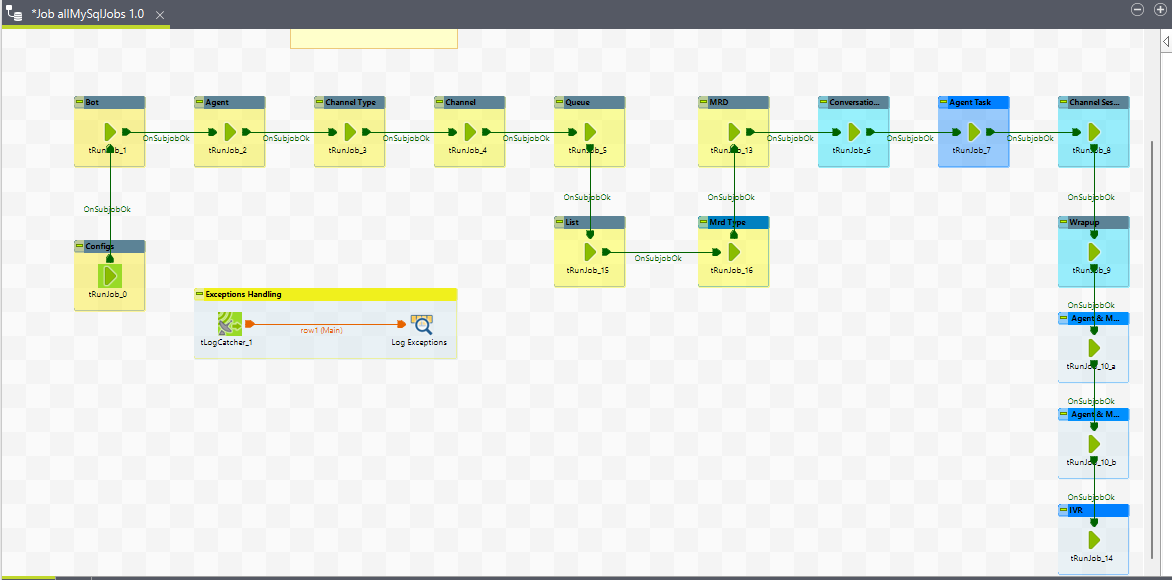
1. allMySqlJobs ETL job:
Purpose
This scheduler job (parent job) orchestrates the execution of multiple MySQL ETL jobs in a specified order. It ensures that each job is executed sequentially, handling both configuration-based and transaction-based ETLs.
Job Components
The job comprises several key components, each representing a step in the ETL process:
-
tRunJob (Manages complex Job systems which need to execute one Job after another).
-
ExceptionHandling (LogCatch)
1. Detailed Job components description:
-
Each
tRunJobcomponent runs a specific MySQL job. -
Configuration-based ETL are designed to handle static data or settings that rarely change.
-
Transaction-based ETL are designed to handle dynamic/operational data and operations that occur frequently.
|
Component |
ETL job |
Type |
|---|---|---|
|
tRunJob_0 |
configs |
configuration |
|
tRunJob_1 |
Bot |
configuration |
|
tRunJob_2 |
Agent |
configuration |
|
tRunJob_3 |
Channel Type |
configuration |
|
tRunJob_4 |
Channel |
configuration |
|
tRunJob_5 |
Queue |
configuration |
|
tRunJob_6 |
Conversation |
Transaction |
|
tRunJob_7 |
Agent Task |
Transaction |
|
tRunJob_8 |
Channel Session |
Transaction |
|
tRunJob_9 |
Wrapup |
Transaction |
|
tRunJob_10_a |
Agent and Mrd states insert |
Transaction |
|
tRunJob_10_b |
Agent and Mrd states - update duration |
Transaction |
|
tRunJob_13 |
Mrd |
configuration |
|
tRunJob_14 |
IVR |
Transaction |
|
tRunJob_15 |
List |
configuration |
|
tRunJob_16 |
Mrd Type |
configuration |
2. Exception Handling
-
LogCatch_1:
-
This component catches and logs exceptions that occur during the execution of the scheduler job.
-
It ensures that any errors are documented for troubleshooting and maintenance.
-
3. Execution Flow
-
The scheduler job starts by executing
tRunJob_0. -
Each subsequent
tRunJobcomponent is triggered upon the successful completion of the previous job. -
If any job fails, the
LogCatch_1component captures the error details. -
The process continues, completing all configuration and transational based jobs while following the linked order.
Job view
2. mysql_job_00_configs
Purpose
This job is designed to load the report configurations into the system. It specifically handles the following configurations:
-
Config 1: Conversation Transcript Download URL
-
Config 2: Conversation Transcript View URL
1. Execution Flow
-
Start:
-
The job starts and initializes the necessary connections and settings.
-
This job consist of two child jobs (Load Configuration 1 and Load Configuration 2)
-
-
Load Configuration 1: Conversation Transcript Download URL:
-
The
tMysqlInput_1component retrieves the existing configuration for the Conversation Transcript Download URL from the MySQL database. -
The
tMap_1component processes and maps the retrieved data. -
The
tMysqlOutput_1component writes the processed data back into the database. -
The
tLogRow_1component logs the processed data for verification.
-
-
Load Configuration 2: Conversation Transcript View URL:
-
The
tMysqlInput_2component retrieves the existing configuration for the Conversation Transcript View URL from the MySQL database. -
The
tMap_2component processes and maps the retrieved data. -
The
tMysqlOutput_2component writes the processed data back into the database. -
The
tLogRow_2component logs the processed data for verification.
-
-
Custom Processing (Optional):
-
The
tJavaRowcomponent executes any custom Java code required for additional processing or calculations on the configuration data.
-
-
Exception Handling:
-
The
LogCatchcomponent captures and logs any exceptions that occur during the job execution for troubleshooting and maintenance.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
2. Job View
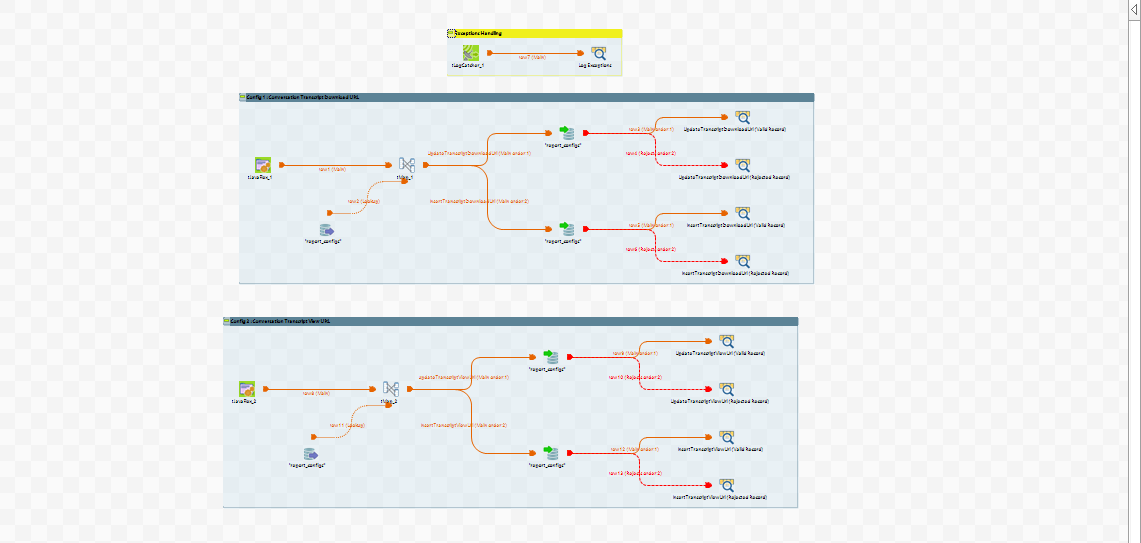
This structured flow ensures that the report configurations for the Conversation Transcript Download URL and View URL are loaded accurately and efficiently into the database.
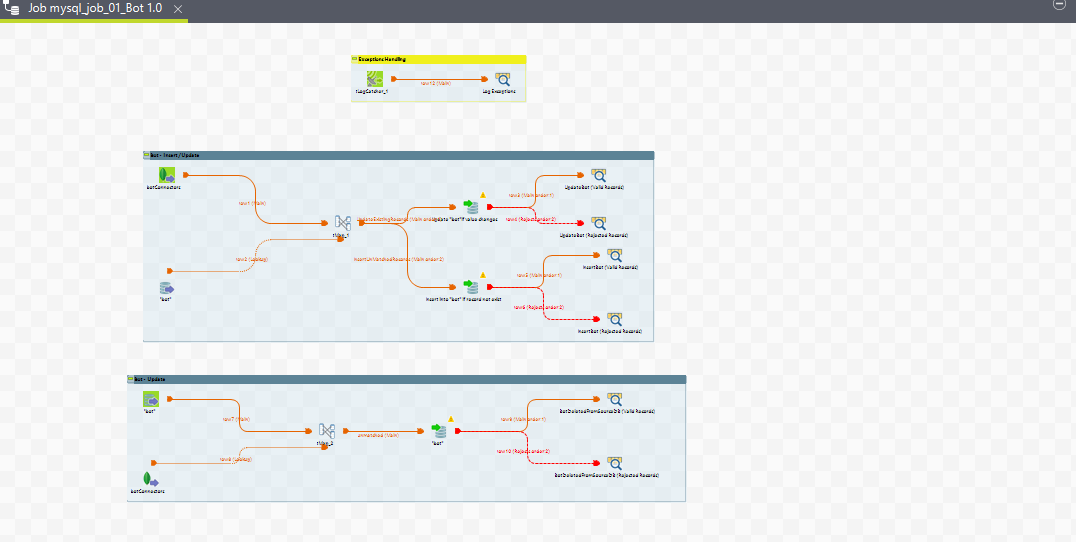
3. mysql_job_01_Bot
Purpose
This job manages the records of a bot configured in the system. The job handles the insertion and updating of bot details, ensuring that each bot's details are correctly maintained in the database.
1. Execution Flow
-
Start:
-
The job starts and initializes the necessary connections and settings.
-
-
Bot - Insert / Update:
-
The
tMysqlInput_1component retrieves the existing bot data from the MySQL database. -
The
tMap_1component processes and maps the retrieved data. -
The
tMysqlOutput_1component writes the processed data into the database. This can involve inserting new bot records or updating existing ones based on the conditions set. -
The
tLogRow_1component logs the processed data for verification.
-
-
Bot - Update:
-
The
tMysqlInput_2component retrieves specific bot data that needs to be updated. -
The
tMap_2component processes and maps the data for updating. -
The
tMysqlOutput_2component writes the updated data back into the database. -
The
tLogRow_2component logs the processed data for verification.
-
-
Exception Handling:
-
The
LogCatchcomponent captures and logs any exceptions that occur during the job execution for troubleshooting and maintenance.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
-
This structured flow ensures that the bot records are accurately inserted and updated in the database, maintaining the integrity and correctness of the bot configuration details.
2. Job View
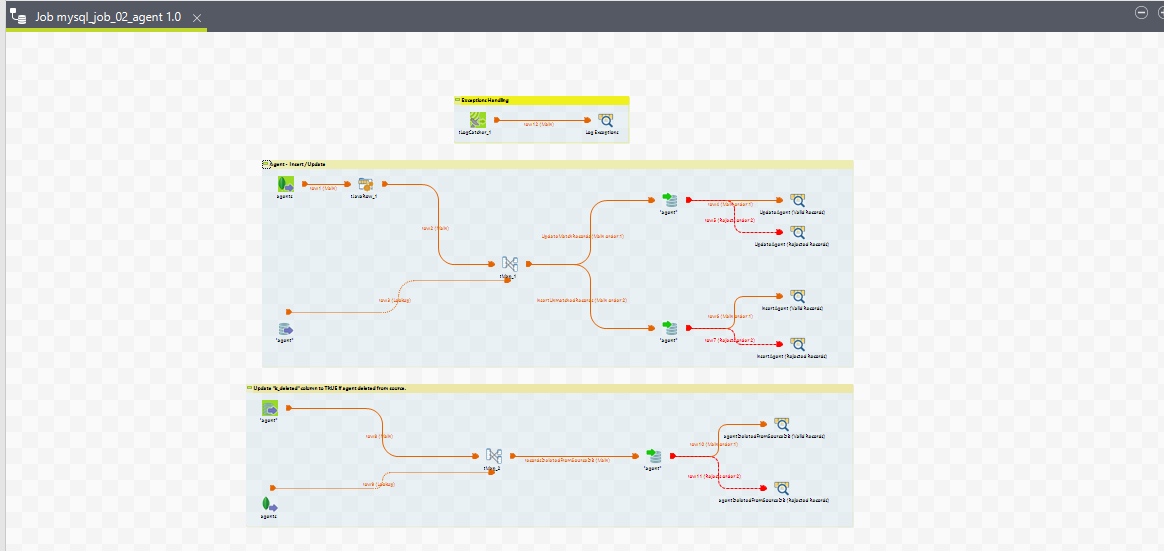
4. mysql_job_02_agent
Purpose
This job manages the records of an agent in the system. The job handles the insertion and updating of agent details, ensuring that each agent's details are correctly maintained in the database. Additionally, it updates the is_deleted column to TRUE if an agent is deleted from the source.
1. Execution Flow
-
Start:
-
The job starts and initializes the necessary connections and settings.
-
-
Agent - Insert / Update:
-
The
tMysqlInput_1component retrieves the existing agent data from the MySQL database. -
The
tMap_1component processes and maps the retrieved data. -
The
tMysqlOutput_1component writes the processed data back into the database. This can involve inserting new agent records or updating existing ones based on the conditions set. -
The
tLogRow_1component logs the processed data for verification.
-
-
Update
is_deletedcolumn to TRUE if agent deleted from source:-
The
tMysqlInput_2component retrieves agent data that has been marked as deleted from the source. -
The
tMap_2component processes and maps the data for updating theis_deletedcolumn toTRUE. -
The
tMysqlOutput_2component writes the updated data back into the database, setting theis_deletedcolumn toTRUEfor the appropriate records. -
The
tLogRow_2component logs the processed data for verification.
-
-
Exception Handling:
-
The
LogCatchcomponent captures and logs any exceptions that occur during the job execution for troubleshooting and maintenance.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
This structured flow ensures that the agent records are accurately inserted, updated, and marked as deleted in the database, maintaining the integrity and correctness of the agent configuration details.
2. Job View
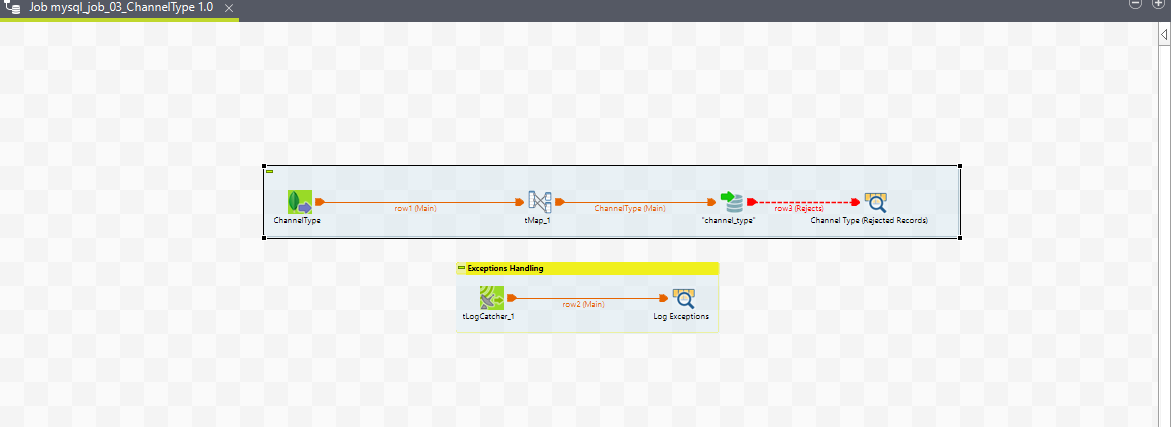
5. mysql_job_03_ChannelType
Purpose
A channel type describes the type/class of the channels, for example, WHATSAPP, SMS, WEB. Multiple channels of a channel type can be created.
1. Execution Flow
-
Start: The job starts and initializes the necessary context variables and connections.
-
Extract Data: The
tMongoDBInput_ChannelTypecomponent extracts channel type data from the source database. -
Transform Data: The extracted data is passed to the
tMap_ChannelTypecomponent, which maps and transforms the input data. -
Load Data: The transformed data is sent to the
tMySQLOutput_ChannelTypecomponent to load the channel type data into the target database. -
Log Exceptions: The
tLogCatcher_ChannelTypecomponent logs any exceptions that occur during the main ETL process. -
Exception Handling: The
tLogCatcher_ExceptionHandlingcomponent catches and logs exceptions. -
End: The job finalizes the process and closes any open connections.
2. Job View
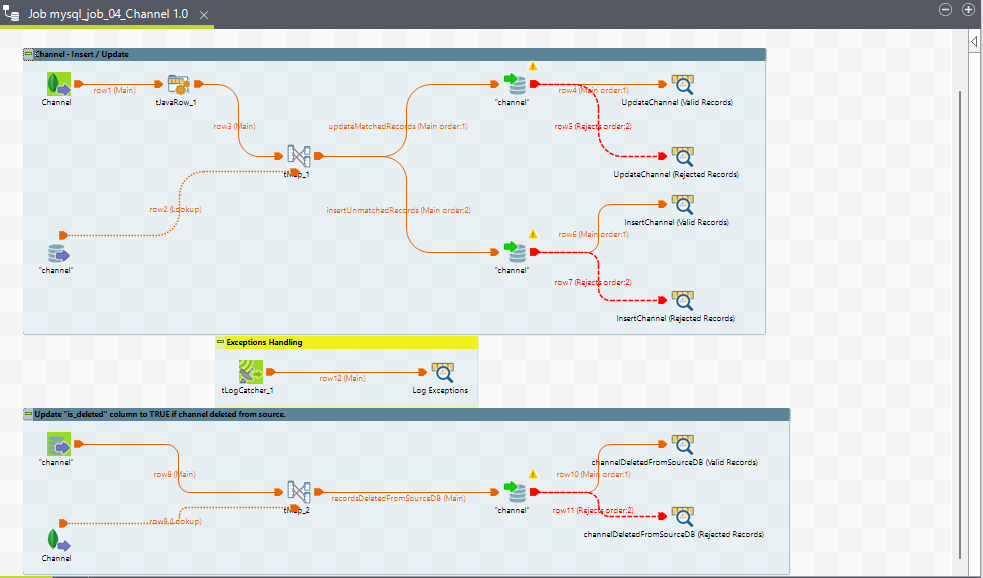
6. mysql_job_04_Channel
Purpose
A channel instance is created when a new communication channel is registered by the system. It includes all the configuration details of a channel, such as the channel name, service identifier, channel mode, etc. A channel is of a particular channel type. For instance, we can create two channels WhatsApp-external and WhatsApp-internal, both of a channel type WHATSAPP.
This ETL job handles the following tasks:
-
Insert or update channel information.
-
Update the "is_deleted" column to TRUE if a channel is deleted from the source.
1. Execution Flow
-
Start: The job starts and initializes the necessary context variables and connections.
Channel - Insert / Update
-
Extract Data: The
tMongoDbInput_Channelextract channel data from channel collection of mongoDB. -
Transform Data: The extracted data is passed to the
tMap_Channelcomponent, which splits the data into streams for updating matched records (updateMatchedRecords) and inserting unmatched records (insertUnmatchedRecords). -
Load Data:
-
The
updateMatchedRecordsstream is sent to thetMySQLOutput_UpdateChannelcomponent to update existing channel records. -
The
insertUnmatchedRecordsstream is sent to thetMySQLOutput_InsertChannelcomponent to insert new channel records.
-
-
Log Exceptions: The
tLogCatcher_Channelcomponent logs any exceptions that occur during the insert/update process.
Update "is_deleted" column to TRUE if channel deleted from source
-
Extract Deleted Data: The
tMysqlInput_DeletedChannelretrieves channel data that has been marked as deleted from the source. -
Transform Deleted Data: The extracted deleted data is passed to the
tMap_UpdateDeletedcomponent for mapping. -
Load Deleted Data: The mapped data is sent to the
tMySQLOutput_UpdateDeletedcomponent to update the "is_deleted" column to TRUE for the corresponding channels. -
Log Exceptions: The
tLogCatcher_UpdateDeletedcomponent logs any exceptions that occur during the update process. -
Exception Handling: The
tLogCatcher_ExceptionHandlingcomponent catches and logs exceptions. -
End: The job finalizes the process and closes any open connections.
2. Job View
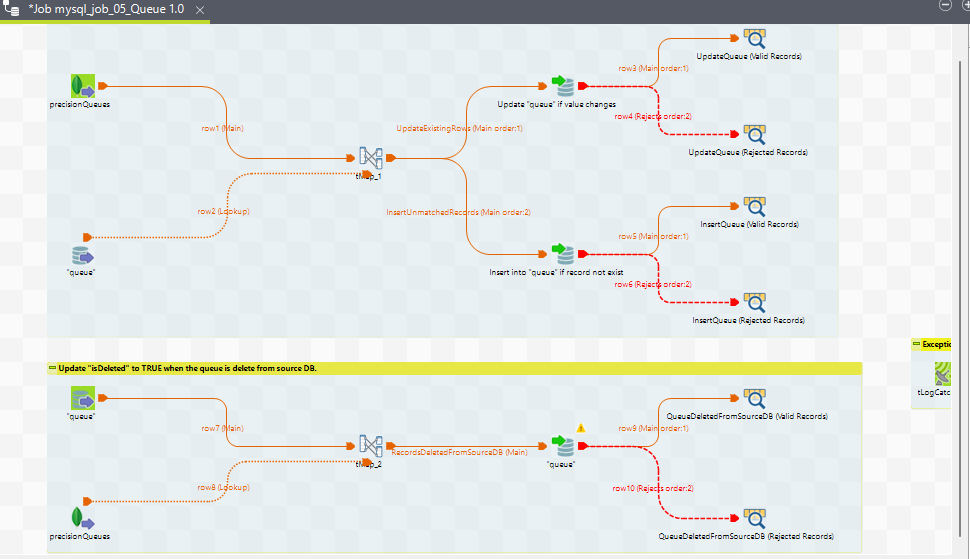
7. mysql_job_05_Queue
Purpose
This ETL job manages the properties of a routing queue. Whenever a human agent is required for a conversation, a request to assign an agent is created by the system and offered to a routing queue. The properties of a single routing queue are inserted as a single record in this table.
This ETL job handles the following tasks:
-
Insert or update queue information.
-
Update the "isDeleted" column to TRUE when the queue is deleted from the source database.
1. Execution Flow
-
Start: The job starts and initializes the necessary context variables and connections.
Queue - Insert / Update
-
Extract Data: The
tMongoDBInput_1 (precisionQueues)component reads queue data from a MongoDB database. -
Transform Data: The extracted data is passed to the
tMap_1component, which splits the data into streams for updating matched records (UpdateExistingRows) and inserting unmatched records (InsertUnmatchedRecords). -
Load Data:
-
The
UpdateExistingRowsstream is sent to thetMySQLOutput_UpdateQueuecomponent to update existing queue records. -
The
InsertUnmatchedRecordsstream is sent to thetMySQLOutput_InsertQueuecomponent to insert new queue records.
-
-
Log Exceptions: The
tLogCatchercomponent logs any exceptions that occur during the insert/update process.
Update "isDeleted" column to TRUE when the queue is deleted from source DB
-
Extract Deleted Data: The
tMySqlDBInput_2 (queue)component reads queue data marked as deleted from a Mysql database. -
Transform Deleted Data: The extracted deleted data is passed to the
tMap_2component for mapping. -
Load Deleted Data: The mapped data is sent to the
tMySQLOutput_UpdateDeletedQueuecomponent to update the "isDeleted" column to TRUE for the corresponding queues. -
Log Exceptions: The
tLogCatchercomponent logs any exceptions that occur during the update process. -
End: The job finalizes the process and closes any open connections.
2. Job View
7. mysql_job_06_conversations
Purpose
The mysql_job_06_conversations job performs ETL operations over conversations in the EFCX system. This job consists of three individual child jobs:
-
Conversation
-
Conversation Participant
-
Conversation Data
Each child job involves different components and targets different tables.
Detailed Job Components Description
1. Conversation ETL Job
-
conversationtDBInput_1 (MySQL)-
Purpose: Fetches the
end_timevalue from the conversation table to get the time of the last record being dumped. -
Component Description: Retrieves the most recent
end_timefrom theconversationtable to determine the starting point for fetching new data.
-
-
tJava
-
Purpose: Implements batch data extraction logic.
-
Component Description: Contains Java code to calculate the number of batches needed for processing.
-
Formula:
totalBatches = Math.ceil(recordCount / (double) batchSize); context.batch_number = totalBatches;
-
-
tLoop
-
Purpose: Handles job run in a loop depending on the value of
context.batch_number. -
Component Description: Uses the calculated batch number to iterate the job execution for fetching and processing data in batches.
-
-
tRest_1
-
Purpose: Uses an API of the historical reports manager component to fetch the required data.
-
API URL:
<FQDN>/historical-reports/stats/conversation?endTime=1900-01-01T00:00:00.000Z&limit=100 -
Component Description: Makes a REST API call to fetch conversation data from the historical reports manager component.
-
-
tExtractJsonFields_1
-
Purpose: Extracts the desired data from JSON fields based on the JSONPath or XPath query.
-
Component Description: Parses the JSON response received from the API and extracts the necessary fields for transformation and loading.
-
-
tJavaRow
-
Purpose: Provides a code editor to enter Java code applied to each row of the flow.
-
Component Description: Maps the
input_rowwithoutput_rowand sends the mapped data to thetMapcomponent.
-
-
tMap
-
Purpose: Performs data transformation and mapping.
-
Component Description: Maps and transforms the data fields according to the target schema requirements.
-
-
conversationtDBOutput_1 (MySQL)-
Purpose: Inserts the processed data into the MySQL
conversationtable. -
Component Description: Writes the transformed conversation data into the
conversationtable in the MySQL database.
-
Execution Flow
-
Start:
-
The job initializes necessary connections and settings.
-
-
Fetch Last Record Time:
-
The
conversationtDBInput_1 component retrieves theend_timeof the last record dumped in theconversationtable.
-
-
Calculate Batches:
-
The tJava component calculates the total number of batches required based on the record count and batch size.
-
-
Iterate Batches:
-
The tLoop component iterates the job execution based on the calculated batch number.
-
-
Fetch Data via API:
-
The tRest_1 component calls the API to fetch conversation data starting from the last
end_time.
-
-
Extract JSON Fields:
-
The tExtractJsonFields_1 component parses the JSON response and extracts the required fields.
-
-
Map Data:
-
The tJavaRow and tMap components transform and map the extracted data to match the target schema.
-
-
Insert Data into MySQL:
-
The
conversationtDBOutput_1 component inserts or updates the processed data into the MySQLconversationtable.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
Job view for conversation child job
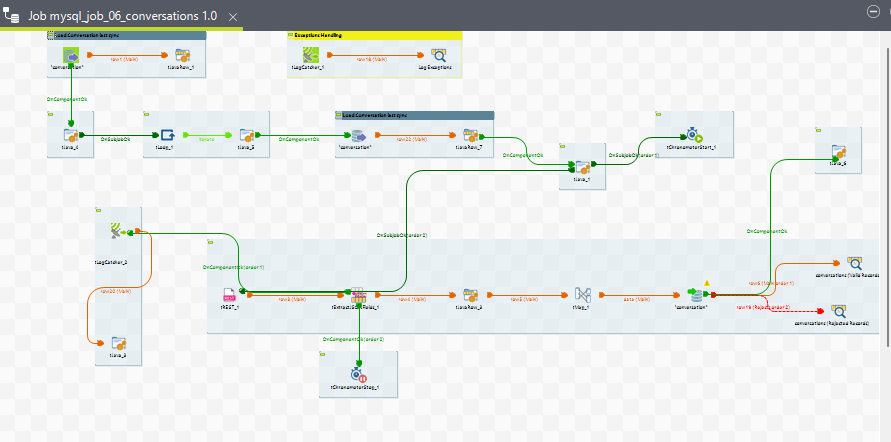
2. Conversation Participant ETL Job
-
conversation_participanttDBInput_1 (MySQL)-
Purpose: Fetches the
record_creation_timevalue from the conversation participant table to get the time of the last record being dumped. -
Component Description: Retrieves the most recent
record_creation_timefrom theconversation_participanttable to determine the starting point for fetching new data.
-
-
tJava
-
Purpose: Implements batch data extraction logic.
-
Component Description: Contains Java code to calculate the number of batches needed for processing.
-
Formula:
totalBatches = Math.ceil(recordCount / (double) batchSize); context.batch_number = totalBatches;
-
-
-
tLoop
-
Purpose: Handles job run in a loop depending on the value of
context.batch_number. -
Component Description: Uses the calculated batch number to iterate the job execution for fetching and processing data in batches.
-
-
tRest_1
-
Purpose: Uses an API of the historical reports manager component to fetch the required data.
-
API URL:
<FQDN>/historical-reports/stats/conversation/participant?endTime=<last_sync_time>&limit=100 -
Component Description: Makes a REST API call to fetch conversation participant data from the historical reports manager component.
-
-
tExtractJsonFields_1
-
Purpose: Extracts the desired data from JSON fields based on the JSONPath or XPath query.
-
Component Description: Parses the JSON response received from the API and extracts the necessary fields for transformation and loading.
-
-
tJavaRow
-
Purpose: Provides a code editor to enter Java code applied to each row of the flow.
-
Component Description: Maps the
input_rowwithoutput_rowand sends the mapped data to thetMapcomponent.
-
-
tMap
-
Purpose: Performs data transformation and mapping.
-
Component Description: Maps and transforms the data fields according to the target schema requirements.
-
-
conversation_participanttDBOutput_1 (MySQL)-
Purpose: Inserts the processed data into the MySQL
conversation_participanttable. -
Component Description: Writes the transformed conversation participant data into the
conversation_participanttable in the MySQL database.
-
Execution Flow for Conversation Participant
-
Start:
-
The job initializes necessary connections and settings.
-
-
Fetch Last Record Time:
-
The
conversation_participanttDBInput_1 component retrieves theend_timeof the last record dumped in theconversation_participanttable.
-
-
Calculate Batches:
-
The tJava component calculates the total number of batches required based on the record count and batch size.
-
-
Iterate Batches:
-
The tLoop component iterates the job execution based on the calculated batch number.
-
-
Fetch Data via API:
-
The tRest_1 component calls the API to fetch conversation participant data starting from the last
end_time.
-
-
Extract JSON Fields:
-
The tExtractJsonFields_1 component parses the JSON response and extracts the required fields.
-
-
Map Data:
-
The tJavaRow and tMap components transform and map the extracted data to match the target schema.
-
-
Insert Data into MySQL:
-
The
conversation_participanttDBOutput_1 component inserts the processed data into the MySQLconversation_participanttable.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
Job view for conversation participant child job
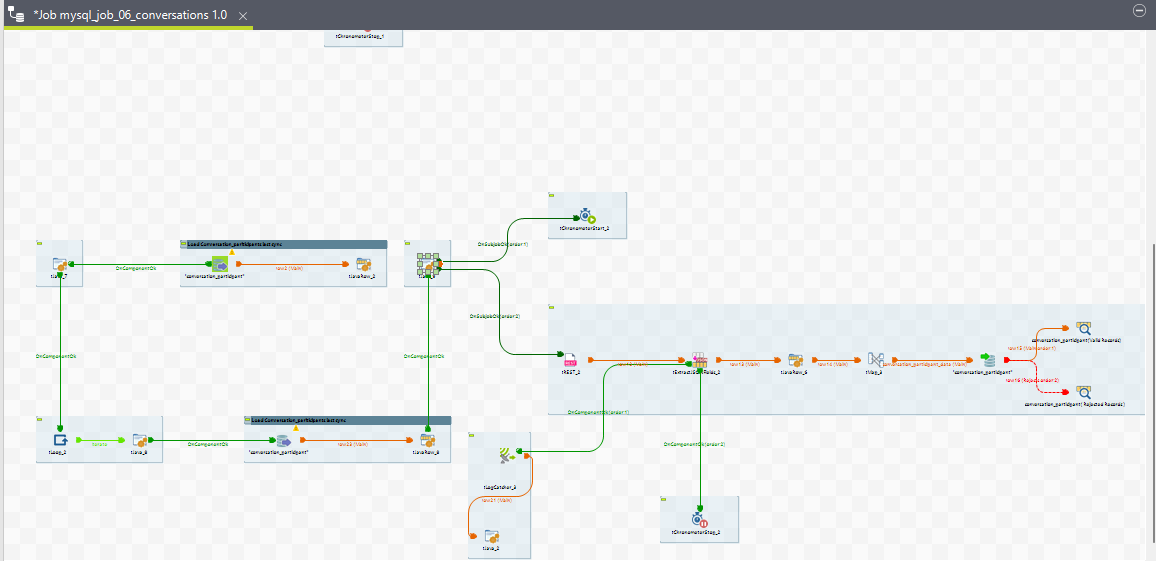
3. Conversation Data ETL Job
-
tMongoDBInput (source)
-
Purpose: Extracts data from MongoDB based on a specific query.
-
MongoDB Query:
{ "$and": [ { "endTime": { "$gt": { "$date": "globalMap.get('conversation_last_sync_context')" } } }, { "conversationData": { "$exists": true, "$type": "object", "$ne": {} } } ] }
-
-
tJavaRow
-
Purpose: Converts
conversationDataObjinto aJSONArrayfor further processing intJavaFlex. -
Component Description: Prepares the conversation data for iteration and transformation.
-
-
tJavaFlex
-
Purpose: Iterates over the
JSONArrayand processes each key-value pair. -
Code:
for (int i = 0; i < jsonArray.length(); i++) { JSONObject jsonObject1 = jsonArray.getJSONObject(i); Iterator<String> keysItr2 = jsonObject1.keys(); while (keysItr2.hasNext()) { String key1 = keysItr2.next(); String value1 = jsonObject1.getString(key1); row9.key = key1; row9.value = value1; } } -
Component Description: Iterates through the JSON array to extract key-value pairs for each conversation data entry.
-
-
tMap
-
Purpose: Performs data transformation and mapping.
-
Component Description: Maps and transforms the data fields according to the target schema requirements.
-
-
conversation_datatDBOutput (MySQL)-
Purpose: Inserts or updates the processed data into the MySQL
conversation_datatable. -
Component Description: Writes the transformed conversation data into the
conversation_datatable in the MySQL database.
-
Execution Flow for Conversation Data
-
Start:
-
The job initializes necessary connections and settings.
-
-
Fetch Data from MongoDB:
-
The tMongoDBInput component retrieves data from the MongoDB database based on the specified query.
-
-
Add conversation data to JSON Array:
-
The tJavaRow component converts the
conversationDataObjinto aJSONArray.
-
-
Process JSON Array:
-
The tJavaFlex component iterates over the
JSONArrayand extracts key-value pairs for each entry.
-
-
Map Data:
-
The tMap component transforms and maps the extracted data to match the target schema.
-
-
Insert Data into MySQL:
-
The
conversation_datatDBOutput component inserts the processed data into the MySQLconversation_datatable.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
Job view for conversation data child job
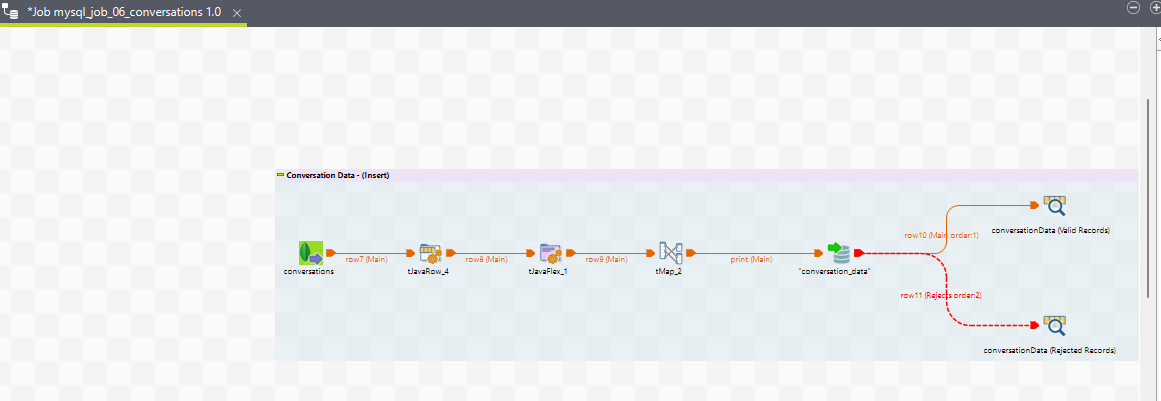
Complete Job view
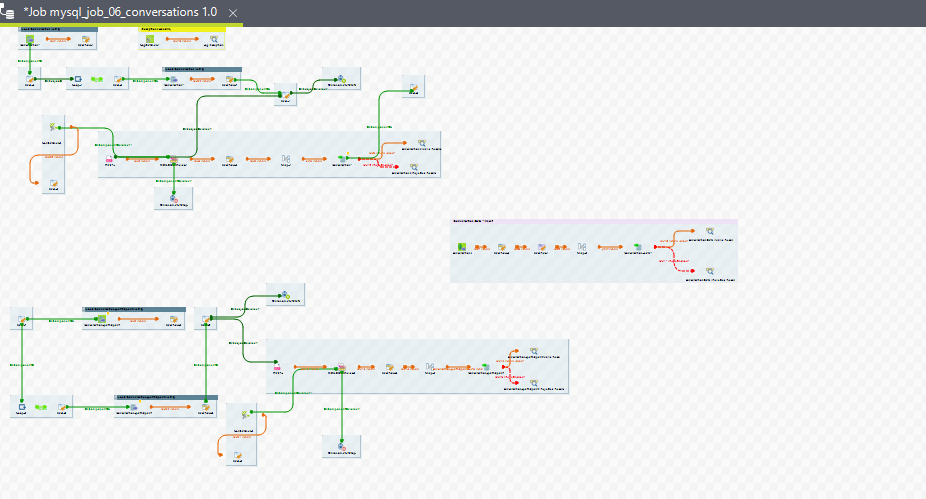
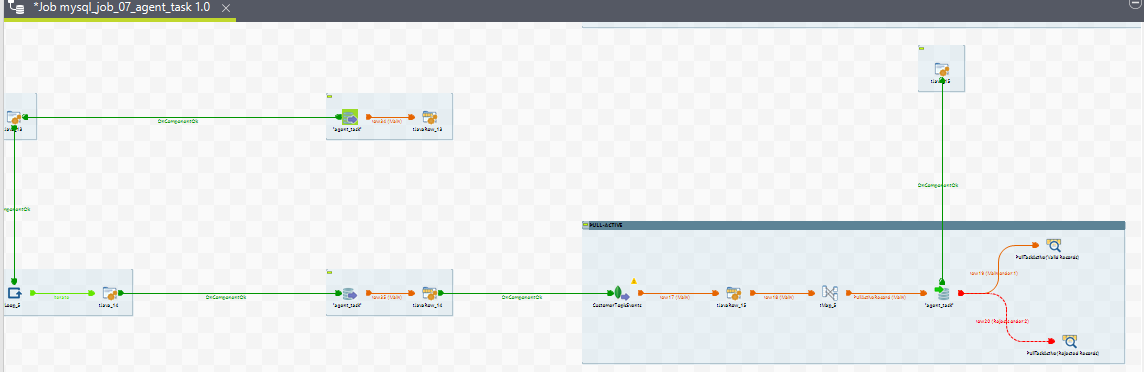
8. mysql_job_07_agent_task
Purpose
The purpose of this ETL job is to compute agent tasks. During a conversation, when a task is reserved for an agent, an agent task is created. The system processes various task states and task media states to compute agent tasks. The task states include ACTIVE, WRAP_UP, and CLOSED, while the task media states include QUEUED, RESERVED, ACTIVE, and CLOSED.
Learn more about Agent Task : Agent Task/Routing Task
The ETL job processes these task on the basis of task media states based on the routing mode (PUSH or PULL) and loads the transformed data into the agent_task table row by row. This means multiple rows may correspond to a single agent_task_id, each row representing a part of the conversation journey.
Sub-jobs
For Routing Mode = PUSH
-
Agent Task QUEUED
{ "$and": [ {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("agent_task_last_sync")+"'}}}, {"cimEvent.name": "TASK_STATE_CHANGED"}, {"cimEvent.data.task.activeMedia": {"$elemMatch": {"state": "QUEUED"}}}, {"cimEvent.data.task.activeMedia.0.requestSession.channel.channelConfig.routingPolicy.routingMode": "PUSH"} ] } -
Agent Task RESERVED
{ "$and": [ {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("agent_task_last_sync")+"'}}}, {"cimEvent.name": "TASK_STATE_CHANGED"}, {"cimEvent.data.task.activeMedia": {"$elemMatch": {"state": "RESERVED"}}}, {"cimEvent.data.task.activeMedia.0.requestSession.channel.channelConfig.routingPolicy.routingMode": "PUSH"} ] } -
Agent Task ACTIVE
{ "$and": [ {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("agent_task_last_sync")+"'}}}, {"cimEvent.name": "TASK_STATE_CHANGED"}, {"cimEvent.data.task.activeMedia": {"$elemMatch": {"state": "ACTIVE"}}}, {"cimEvent.data.task.activeMedia.0.requestSession.channel.channelConfig.routingPolicy.routingMode": "PUSH"} ] } -
Agent Task CLOSED
{ "$and": [ {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("agent_task_last_sync")+"'}}}, {"cimEvent.name": "TASK_STATE_CHANGED"}, {"cimEvent.data.task.activeMedia": {"$elemMatch": {"state": "CLOSED"}}}, {"cimEvent.data.task.activeMedia.0.requestSession.channel.channelConfig.routingPolicy.routingMode": "PUSH"} ] }
For Routing Mode = PULL (For OUTBOUND/Agent Initiated conversations)
-
PULL ACTIVE
{ "$and": [ {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("agent_task_last_sync")+"'}}}, {"cimEvent.name": "TASK_STATE_CHANGED"}, {"cimEvent.data.task.activeMedia": {"$elemMatch": {"state": "ACTIVE"}}}, {"cimEvent.channelSession.channel.channelConfig.routingPolicy.routingMode": "PULL"} ] }
-
PULL CLOSED
{ "$and": [ {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("agent_task_last_sync")+"'}}}, {"cimEvent.name": "TASK_STATE_CHANGED"}, {"cimEvent.data.task.activeMedia": {"$elemMatch": {"state": "CLOSED"}}}, {"cimEvent.channelSession.channel.channelConfig.routingPolicy.routingMode": "PULL"} ] }
Components Description
-
tDBInput_1 (MySQL)
-
Purpose: Fetches the
record_creation_timevalue from theagent_tasktable to get the time of the last record being dumped. -
Component Description: Retrieves the most recent
record_creation_timefrom theconversation_participanttable to determine the starting point for fetching new data.
-
-
tJava
-
Purpose: Implements batch data extraction logic.
-
Component Description: Contains Java code to calculate the number of batches needed for processing.
-
Formula:
totalBatches = Math.ceil(recordCount / (double) batchSize); context.batch_number = totalBatches;
-
-
tLoop
-
Purpose: Handles job run in a loop depending on the value of
context.batch_number. -
Component Description: Uses the calculated batch number to iterate the job execution for fetching and processing data in batches.
-
-
tMongoDBInput_1 (CustomerTopicEvents)
-
Purpose: Extraction based on the above mentioned queries.
-
-
tJavaRow
-
Purpose: Provides a code editor to enter Java code applied to each row of the flow.
-
Component Description: Maps the
input_rowwithoutput_rowand sends the mapped data to thetMapcomponent.
-
-
tMap
-
Purpose: Performs data transformation and mapping.
-
Component Description: Maps and transforms the data fields according to the target schema requirements.
-
-
tDBOutput_1 (MySQL)
-
Purpose: Inserts the processed data into the MySQL
agent_tasktable. -
Component Description: Writes the transformed agent task data into the
agent_tasktable in the MySQL database.
-
Execution Flow
-
Start: The job starts and initializes the necessary context variables and connections.
For each sub-job (e.g., Agent Task QUEUED, RESERVED, ACTIVE, CLOSED)
-
Extract Data: The
tMongoDBInput_1 (CustomerTopicEvents)component reads data based on the specified query. -
Transform Data: The extracted data is passed to the
tJavaRowcomponent for mapping and transformation. -
Load Data: The transformed data is sent to the
tMapcomponent for further processing and then loaded into the MySQLagent_tasktable using thetDBOutput_1component. -
Log Exceptions: The
tLogCatchercomponent logs any exceptions that occur during the process. -
End: The job finalizes the process and closes any open connections.
View for all the sub jobs of Agent Task ETL job
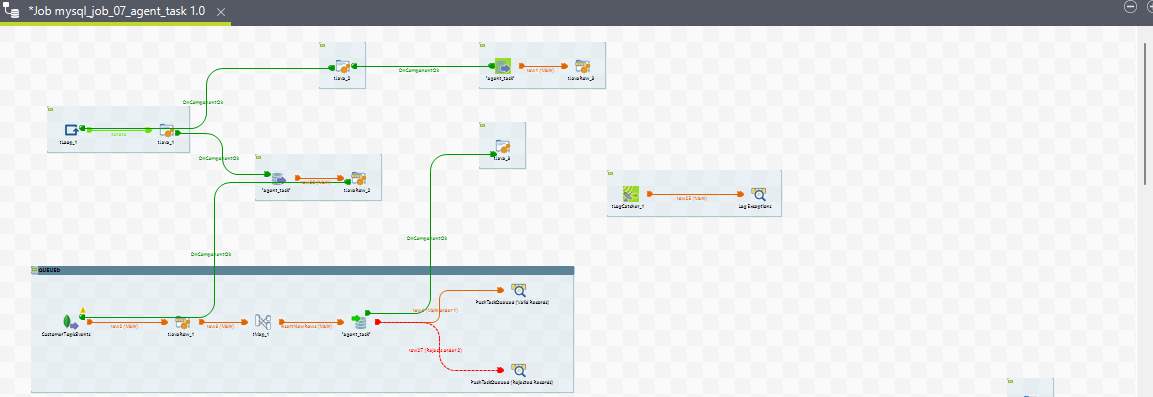
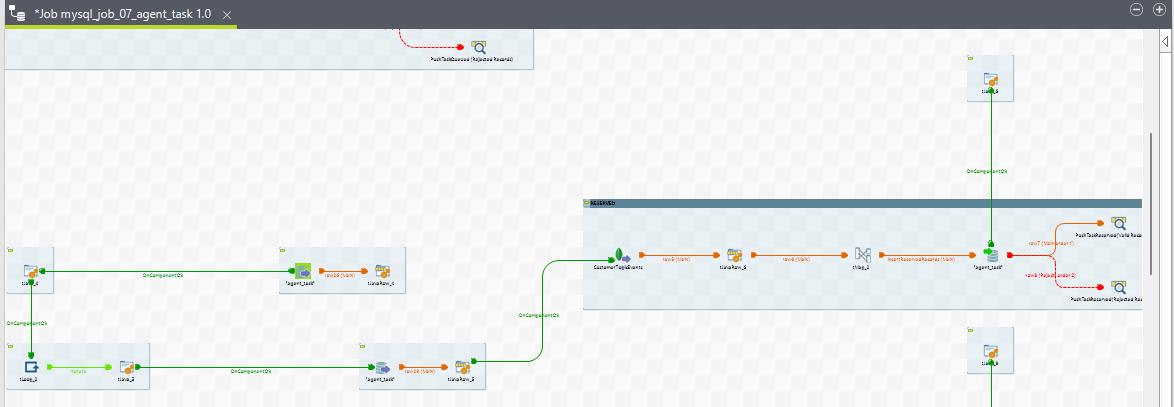
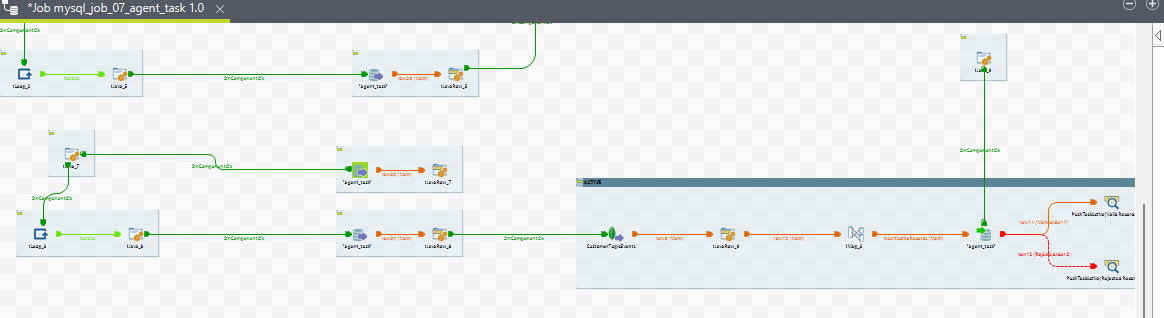
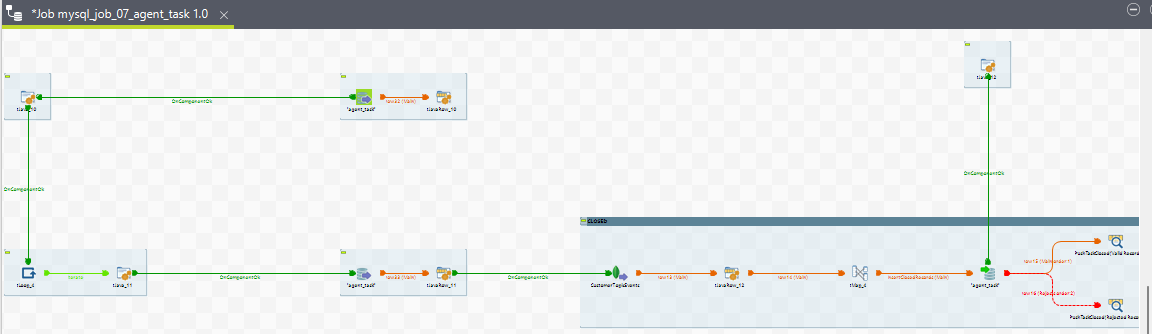
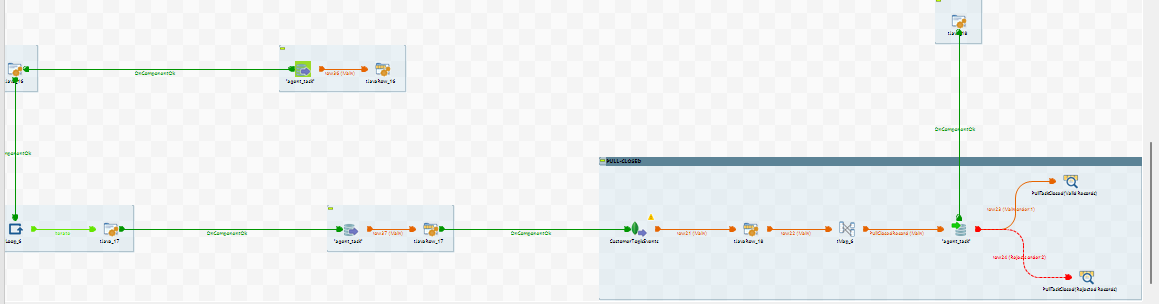
9. mysql_job_08_ChannelSession
Purpose
The mysql_job_08_ChannelSession job performs ETL operations for channel session instances in the system. A channel session instance is created when a customer's new chat session is started on a particular channel, such as WhatsApp or SMS. Each chat session on different channels results in a new channel session instance. The channel session instance ends when the chat is over on the associated channel.
Execution Flow for Channel Session Data
-
Start:
-
The job initializes necessary connections and settings.
-
-
Fetch Data from MySQL:
-
The
channel_sessiontDBInput component retrieves the most recentrecord_creation_timefrom thechannel_sessiontable to determine the starting point for fetching new data.
-
-
Calculate Batches:
-
The tJava component calculates the number of batches needed for processing using the formula:
totalBatches = Math.ceil(recordCount / (double) batchSize); context.batch_number = totalBatches;
-
-
Iterate with Loop:
-
The tLoop component iterates the job execution for fetching and processing data in batches.
-
-
Fetch Data from API:
-
The tRest_1 component makes a REST API call to fetch channel session data from the historical reports manager component using the URL:
https://<FQDN>//historical-reports/stats/channelSession?endTime=<channel_session_last_sync>&limit=<context.batch_size>.
-
-
Extract JSON Fields:
-
The tExtractJsonFields_1 component parses the JSON response and extracts the necessary fields for transformation and loading.
-
-
Map Data:
-
The tMap component maps and transforms the data fields according to the target schema requirements.
-
-
Insert Data into MySQL:
-
The
channel_sessiontDBOutput component inserts or updates the processed data into the MySQLchannel_sessiontable.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
Job View
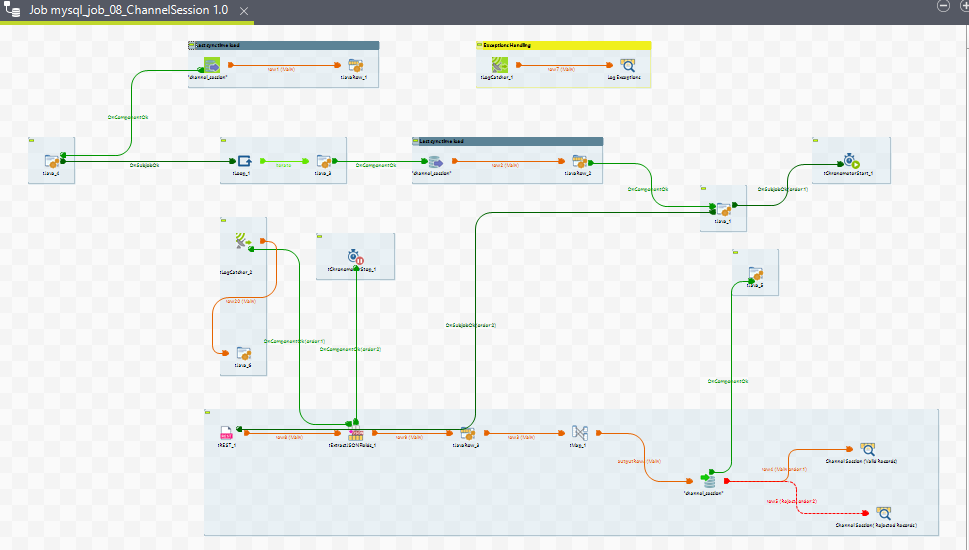
10. mysql_job_09_Wrapup
Purpose
The purpose of this ETL job is to process wrap-ups and wrap-up notes associated with conversations handled by agents. Wrap-ups are concluding notes added to conversations to summarize what the conversation was about. Agents can provide wrap-ups during or after the conversation, and they can also add notes independently at any time. This ETL job consists of two sub-jobs: one for processing wrap-ups and another for wrap-up notes.
Sub-jobs
1. Wrapups
Source: CustomerTopicEvents (tMongoDBInput_1)
Query:
{ "$and": [ {"cimEvent.data.body.type": "WRAPUP"}, {"cimEvent.data.body.wrapups": {"$exists": true, "$type": "array", "$ne": []}}, {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("wrapup_last_sync")+"'"}}} ] }
2. Wrapup Notes
Source: CustomerTopicEvents (tMongoDBInput_1)
Query:
{ "$and": [ {"cimEvent.data.body.type": "WRAPUP"}, {"cimEvent.data.body.wrapups": {"$exists": true, "$type": "array", "$eq": []}}, {"recordCreationTime": {"$gt": {"$date": "'"+globalMap.get("wrapup_last_sync")+"'"}}} ] }
Components Description
-
tDBInput_1 (MySQL)
-
Purpose: Fetches the
record_creation_timevalue from thewrapup_detailtable to get the time of the last record being dumped. -
Component Description: Retrieves the most recent
record_creation_timefrom thewrapup_detailtable to determine the starting point for fetching new data.
-
-
tJava
-
Purpose: Implements batch data extraction logic.
-
Component Description: Contains Java code to calculate the number of batches needed for processing.
-
Formula:
totalBatches = Math.ceil(recordCount / (double) batchSize); context.batch_number = totalBatches;
-
-
tLoop
-
Purpose: Handles job run in a loop depending on the value of
context.batch_number. -
Component Description: Uses the calculated batch number to iterate the job execution for fetching and processing data in batches.
-
-
tMongoDBInput_1 (CustomerTopicEvents)
-
Purpose: Extraction based on the mentioned queries.
-
-
tJavaRow
-
Purpose: Provides a code editor to enter Java code applied to each row of the flow.
-
Component Description: Maps the
input_rowwithoutput_rowand sends the mapped data to thetMapcomponent.
-
-
tMap
-
Purpose: Performs data transformation and mapping.
-
Component Description: Maps and transforms the data fields according to the target schema requirements.
-
-
tDBOutput_1 (MySQL)
-
Purpose: Inserts the processed data into the MySQL
wrapup_detailtable. -
Component Description: Writes the transformed wrap-up data into the
wrapup_detailtable in the MySQL database.
-
Execution Flow
-
Start: The job starts and initializes the necessary context variables and connections.
For each sub-job (e.g., Wrapups, Wrapup Notes)
-
Extract Data: The
tMongoDBInput_1 (CustomerTopicEvents)component reads data based on the specified query. -
Transform Data: The extracted data is passed to the
tJavaRowcomponent for mapping and transformation. -
Load Data: The transformed data is sent to the
tMapcomponent for further processing and then loaded into the MySQLwrapup_detailtable using thetDBOutput_1component. -
Log Exceptions: The
tLogCatchercomponent logs any exceptions that occur during the process. -
End: The job finalizes the process and closes any open connections.
Job View
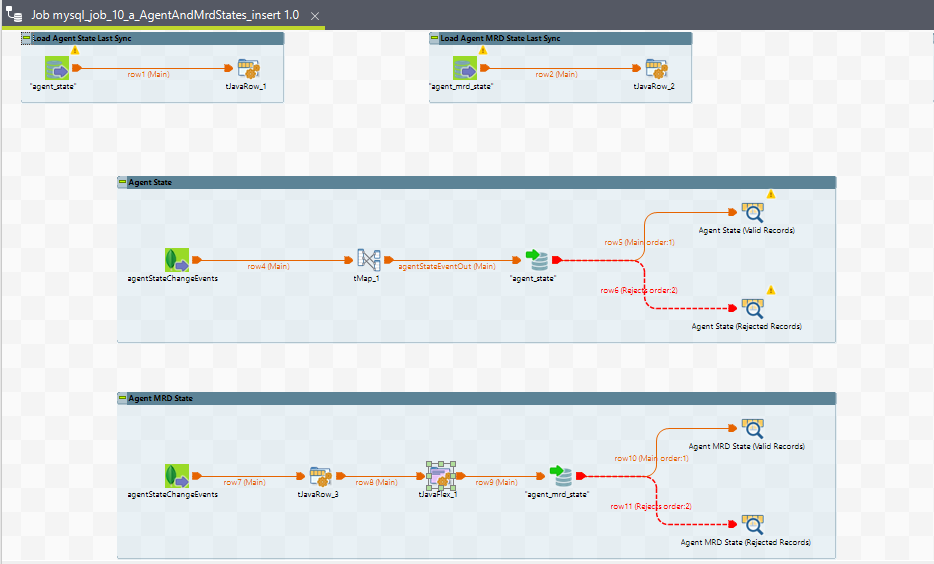
11. mysql_job_10_a_AgentAndMrdStates_insert
Purpose
This ETL job loads the agent and agent MRD (Media Routing Domain) states into a historical database. The agent state data provides information about the current state of the agent, while the MRD state data provides information about the states of different media routing domains that the agent is handling. The duration of the states is also recorded, with specific values indicating the current state or logout events.
Child Jobs
1. Agent State
Source: agentStateChangeEvents (tMongoDBInput_1)
Query:
{ "$and": [ {"name": "AGENT_STATE_CHANGED"}, {"data.agentStateChanged": true}, {"data.agentPresence.stateChangeTime": {"$gt": {"$date": "'"+globalMap.get("agent_state_last_sync")+"'"}}} ] }
Target Table: agent_state (MySQL)
2. Agent MRD State
Source: agentStateChangeEvents (tMongoDBInput_1)
Query:
{ "$and": [ {"data.agentPresence.agentMrdStates": {"$elemMatch": {"stateChangeTime": {"$gt": {"$date": "'"+globalMap.get("agent_mrd_state_last_sync")+"'"}}}}}, { "$or": [ {"$and": [{"name": "AGENT_STATE_CHANGED"}, {"data.agentStateChanged": false}]}, {"$and": [ {"name": "AGENT_STATE_CHANGED"}, {"data.agentStateChanged": true}, {"data.agentPresence.state.name": {"$ne": "READY"}} ]} ] } ] }
Target Table: agent_mrd_state (MySQL)
Components Description
-
Load Agent State Last Sync
-
Component: tDBInput_1 (MySQL)
-
Purpose: Fetches the last synchronization time(end_time) for agent states from the
agent_statetable. -
Component Description: Retrieves the most recent
stateChangeTimeto determine the starting point for fetching new agent state data.
-
-
Load Agent MRD State Last Sync
-
Component: tDBInput_2 (MySQL)
-
Purpose: Fetches the last synchronization time(end_time) for agent MRD states from the
agent_mrd_statetable. -
Component Description: Retrieves the most recent
stateChangeTimeto determine the starting point for fetching new agent MRD state data.
-
-
Agent State Extraction and Transformation
-
Component: tMongoDBInput_1 (agentStateChangeEvents)
-
Purpose: Extracts agent state data based on the specified query.
-
Component: tMap_1
-
Purpose: Maps and transforms the agent state data according to the target schema requirements.
-
Target Table:
agent_state(MySQL)
-
-
Agent MRD State Extraction and Transformation
-
Component: tMongoDBInput_2 (agentStateChangeEvents)
-
Purpose: Extracts agent MRD state data based on the specified query.
-
Component: tJavaRow_1
-
Purpose: Applies Java code to process each row of the extracted data.
-
Component: tJavaFlex_1
-
Purpose: Additional transformation logic for the MRD state data.
-
Target Table:
agent_mrd_state(MySQL)
-
Execution Flow
-
Start: The job starts and initializes the necessary context variables and connections.
For each sub-job (e.g., Agent State, Agent MRD State)
-
Load Last Sync Time: The
tDBInputcomponents fetch the last synchronization times for both agent states and agent MRD states. -
Extract Data: The
tMongoDBInputcomponents read data based on the specified queries. -
Transform Data: The extracted data is passed through the
tMap,tJavaRow, andtJavaFlexcomponents for mapping and transformation. -
Load Data: The transformed data is sent to the
agent_stateandagent_mrd_statetables in the MySQL database using the appropriatetDBOutputcomponents. -
Log Exceptions: The
tLogCatchercomponent logs any exceptions that occur during the process. -
End: The job finalizes the process and closes any open connections.
Job View
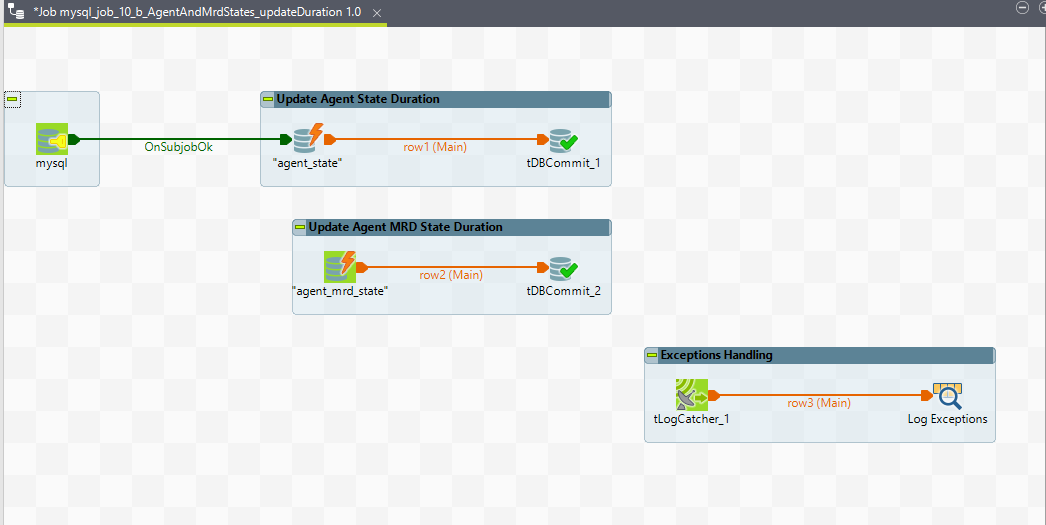
12. mysql_job_10_b_AgentAndMrdStates_updateDuration
Purpose
This ETL job updates the duration of agent states and agent MRD (Media Routing Domain) states in the historical database. The duration indicates the time an agent or MRD has spent in a particular state. A duration of -1 means the agent or MRD is currently in this state, and a duration of 0 means the agent or MRD has logged out.
Components Description
For Updating Agent State Duration
-
tDBConnection_1 (MySQL)
-
Purpose: Establishes a connection to the MySQL database.
-
-
tDBRow_1 (MySQL)
-
Purpose: Executes the SQL query to update the duration of agent states.
-
Query:
UPDATE agent_state a1 JOIN ( SELECT login_date_time, agent_id, state_change_time, LEAD(state_change_time) OVER (PARTITION BY login_date_time, agent_id ORDER BY state_change_time ASC) AS next_state_time, TIMESTAMPDIFF(SECOND, state_change_time, LEAD(state_change_time) OVER (PARTITION BY login_date_time, agent_id ORDER BY state_change_time ASC)) AS duration FROM agent_state ) a2 ON a1.login_date_time = a2.login_date_time AND a1.agent_id = a2.agent_id AND a1.state_change_time = a2.state_change_time SET a1.duration = a2.duration WHERE a1.duration = -1 AND a2.next_state_time IS NOT NULL;
-
-
tDBCommit_1 (MySQL)
-
Purpose: Commits the transaction to ensure the changes are saved in the database.
-
For Updating Agent MRD State Duration
-
tDBRow_2 (MySQL)
-
Purpose: Executes the SQL query to update the duration of agent MRD states.
-
Query:
UPDATE agent_mrd_state a1 JOIN ( SELECT login_date_time, agent_id, mrd_id, state_change_time, LEAD(state_change_time) OVER (PARTITION BY login_date_time, agent_id, mrd_id ORDER BY state_change_time ASC) AS next_state_time, TIMESTAMPDIFF(SECOND, state_change_time, LEAD(state_change_time) OVER (PARTITION BY login_date_time, agent_id, mrd_id ORDER BY state_change_time ASC)) AS duration FROM agent_mrd_state ) a2 ON a1.login_date_time = a2.login_date_time AND a1.agent_id = a2.agent_id AND a1.state_change_time = a2.state_change_time AND a1.mrd_id = a2.mrd_id SET a1.duration = a2.duration WHERE a1.duration = -1 AND a2.next_state_time IS NOT NULL; -
-
tDBCommit_2 (MySQL)
-
Purpose: Commits the transaction to ensure the changes are saved in the database.
-
Execution Flow
-
Start: The job starts and initializes the necessary context variables and connections.
For Updating Agent State Duration
-
Establish Connection: The
tDBConnection_1component establishes a connection to the MySQL database. -
Execute Query: The
tDBRow_1component runs the SQL query to update the duration of agent states. -
Commit Changes: The
tDBCommit_1component commits the transaction to save the changes in the database.
For Updating Agent MRD State Duration
-
Execute Query: The
tDBRow_2component runs the SQL query to update the duration of agent MRD states. -
Commit Changes: The
tDBCommit_2component commits the transaction to save the changes in the database. -
End: The job finalizes the process and closes any open connections.
Job View
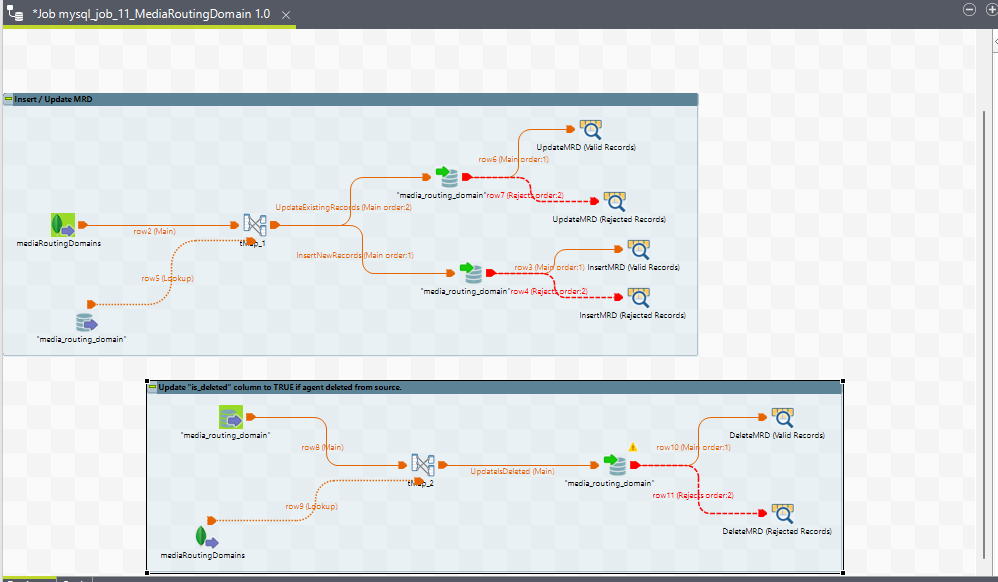
13. mysql_job_11_MediaRoutingDomain
Purpose
The mysql_job_11_MediaRoutingDomain job is designed to perform ETL operations for Media Routing Domains (MRDs) in the system. MRDs are configurations that define the routing of media types (e.g., voice, chat, email) within the contact center system.
Learn more : https://expertflow-docs.atlassian.net/l/cp/PJi67tDR
1. Execution Flow
-
Start:
-
The job starts and initializes the necessary connections and settings.
-
-
Agent - Insert / Update:
-
The
tMysqlInput_1component retrieves the existing MRD data from the MySQL database. -
The
tMap_1component processes and maps the retrieved data. -
The
tMysqlOutput_1component writes the processed data back into the database. This can involve inserting new agent records or updating existing ones based on the conditions set. -
The
tLogRow_1component logs the processed data for verification.
-
-
Update
is_deletedcolumn to TRUE if agent deleted from source:-
The
tMysqlInput_2component retrieves agent data that has been marked as deleted from the source. -
The
tMap_2component processes and maps the data for updating theis_deletedcolumn toTRUE. -
The
tMysqlOutput_2component writes the updated data back into the database, setting theis_deletedcolumn toTRUEfor the appropriate records. -
The
tLogRow_2component logs the processed data for verification.
-
-
Exception Handling:
-
The
LogCatchcomponent captures and logs any exceptions that occur during the job execution for troubleshooting and maintenance.
-
-
End:
-
The job completes, and all connections and resources are closed and released.
-
Job View
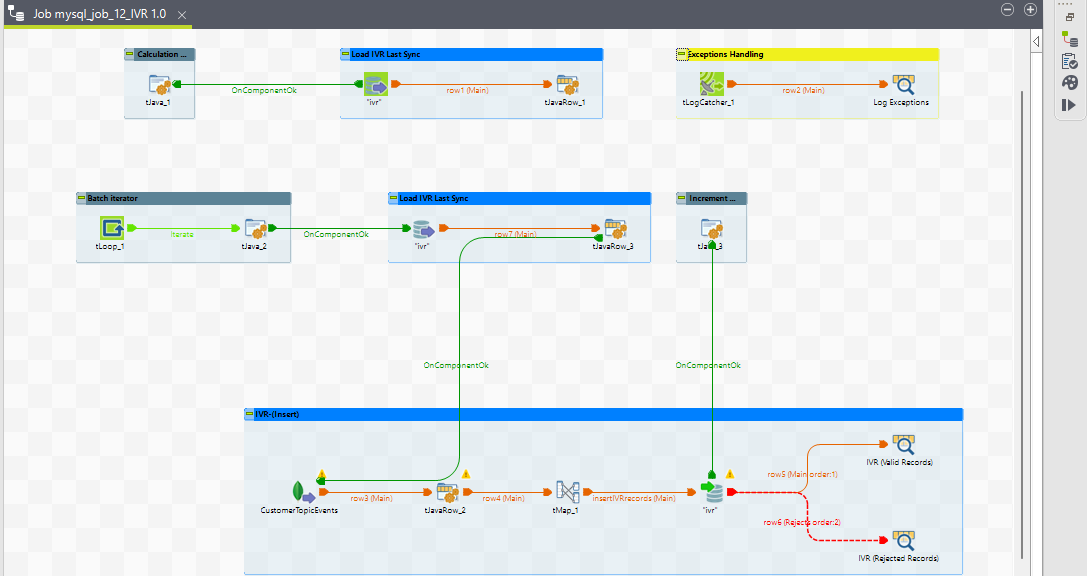
14. mysql_job_12_IVR
Purpose
This ETL job loads data from the IVR_AGGREGATED_ACTIVITY event into a historical database. It extracts records from a MongoDB source based on a specific query and inserts valid records into a MySQL target table while handling any exceptions.
Components Description
Main Job Flow
-
tJava_1 (Calculation)
-
Purpose: Performs batch size calculations and context initializations before loading the IVR last sync time.
-
Type: Custom Java code execution.
-
-
tJavaRow_1 (Load IVR Last Sync)
-
Purpose: Loads the last synchronization time for IVR records.
-
Type: Executes a custom Java code to retrieve the last sync time and set it in global variable.
-
-
tJavaRow_3 (Load IVR Last Sync)
-
Purpose: Another component for loading the IVR last sync time, possibly for different scope or retry mechanism.
-
Type: Executes custom Java code.
-
-
tJava_3 (Increment)
-
Purpose: Increments the batch iterator or handles loop continuation.
-
Type: Custom Java code execution.
-
-
tMongoDBInput (CustomerTopicEvents)
-
Purpose: Extracts records from the MongoDB source.
-
Query:
{ "$and": [ { "recordCreationTime": { "$gt": { "$date": '"+globalMap.get("ivr_last_sync")+"' } } }, { "cimEvent.type": "ACTIVITY" }, { "cimEvent.name": "IVR_AGGREGATED_ACTIVITY" } ] } -
-
tMap_1 (IVR - Insert)
-
Purpose: Maps the extracted data from MongoDB to the MySQL target structure.
-
Type: Data mapping component.
-
-
tDBOutput (Insert IVR Records)
-
Purpose: Inserts valid IVR records into the MySQL target table.
-
-
tDBOutput (IVR - Valid Records)
-
Purpose: logs valid records into the main MySQL target table.
-
-
tDBOutput (IVR - Rejected Records)
-
Purpose: logs rejected records into a separate MySQL table for further inspection.
-
Batch Processing
-
tLoop_1 (Batch Iterator)
-
Purpose: Iterates through batches of data for processing.
-
Type: Loop iteration component.
-
-
tJava_2 (Batch Iterator)
-
Purpose: Custom Java code for batch iteration logic.
-
Exception Handling
-
tLogCatcher_1 (Exceptions Handling)
-
Purpose: Captures and logs exceptions that occur during the ETL process.
-
Type: Log catcher component.
-
-
tLogRow_2 (Log Exceptions)
-
Purpose: Logs captured exceptions for debugging and analysis.
-
Type: Log output component.
-
Execution Flow
-
Start: The job starts and initializes necessary context variables and connections.
-
Load IVR Last Sync: Retrieves the last synchronization time for IVR records using
tJavaRow_1andtJavaRow_3. -
Batch Iteration: Iterates through batches of data using
tLoop_1andtJava_2. -
Extract Data: Extracts data from the MongoDB source based on the query using
tMongoDBInput. -
Map Data: Maps the extracted data to the target structure using
tMap_1. -
Insert Valid Records: Inserts valid IVR records into the MySQL target table using
tDBOutput. -
Insert Rejected Records: logs rejected records for further inspection using
tDBOutput_rejected records. -
Increment Batch: Increments the batch iterator using
tJava_3. -
Exception Handling: Captures and logs any exceptions using
tLogCatcher_1andtLogRow_2. -
End: The job finalizes the process and closes any open connections.
Job View
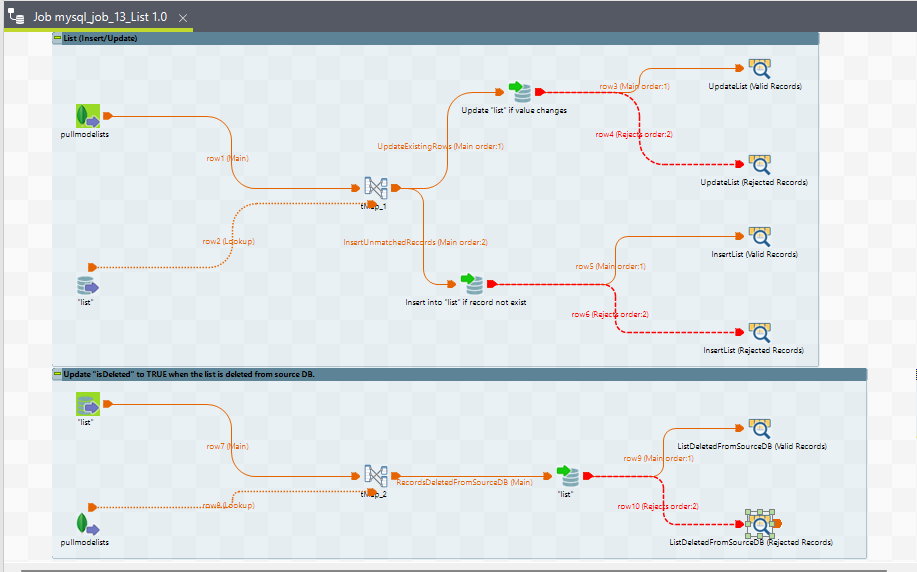
15. mysql_job_13_List
Purpose
This ETL job is designed to record the properties of routing lists. Whenever a human agent is required for a conversation, a request is created by the system and appears in a routing list. This job ensures that the properties of each routing list are inserted as a single record into the target table.
Execution Flow
-
Start: The job begins by initializing the necessary components and connections.
-
Extract Data: The
tMongoDBInputcomponent extracts records from theroutingListscollection in MongoDB based on the defined query. -
Map Data: The
tMapcomponent maps the extracted data to the schema of the MySQL target table. -
Insert Records: The
tDBOutputcomponent inserts the transformed data into therouting_listtable in the MySQL database. -
End: The job completes the process by closing any open connections and finalizing the execution.
Notes
-
Configurational ETL: This job is primarily a configurational ETL, focusing on inserting or updating records related to routing lists in the target database.
-
Exception Handling: Ensure that any errors or issues encountered during data extraction or insertion are properly logged and managed.
Job View
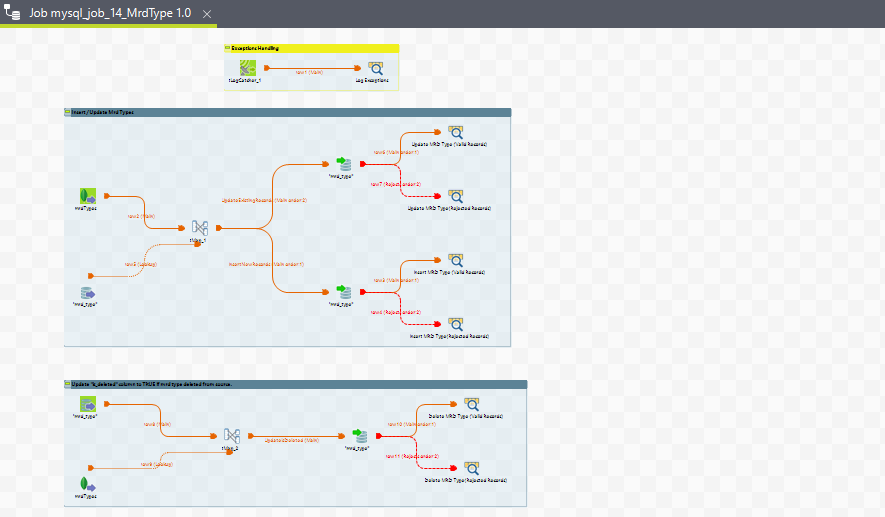
16. mysql_job_14_MrdType
Purpose
This ETL job is designed to manage and update the MrdType supporting table used for the media routing domain. It ensures that the MrdType information is up-to-date in the target database by performing insert, update, and delete operations as required.
Example MongoDB Document for MrdType
{
"_id": {
"$oid": "64f6edf8b89b71cc6cb60917"
},
"name": "CHAT",
"managedByRe": true,
"autoJoin": true,
"interruptible": true,
"_class": "com.ef.cim.objectmodel.MrdType"
}
Execution Flow
-
Start: The job begins by initializing the necessary components and connections.
-
Extract Data: The
tMongoDBInputcomponent extracts records from themrdTypecollection in MongoDB (routing engine database). -
Map Data: The
tMapcomponent maps the extracted data to the schema of the MySQL target table. -
Update Existing Records: The
tDBOutputcomponent updates records in themrd_typetable if changes are detected. -
Insert New Records: The
tDBOutputcomponent inserts new records into themrd_typetable if they do not already exist. -
Mark Records as Deleted: The
tDBOutputcomponent updates theisDeletedfield toTRUEfor records that have been deleted from the source MongoDB collection. -
Exception Handling: The
tLogCatchercomponent captures and logs any exceptions during the ETL process. -
End: The job completes the process by closing any open connections and finalizing the execution.
Notes
-
Supporting Table: This job manages a supporting table for the media routing domain, ensuring that the
MrdTypeinformation is accurate and up-to-date. -
Exception Handling: Proper exception handling is in place to ensure that any errors or issues are logged and managed appropriately.
Job View