ActiveMQ is bundle with Jolokia which provides a RESTful interface to ActiveMQ’s JMX capabilities. The Jolokia agent (JAR file) has been already integrated into the ActiveMQ distribution and it's ready to use out of the box. So we don't need to include any type of metrics exporting utility inside the ActiveMQ package. Jolokia exposes the JMX API of an application through an HTTP interface. Telegraf communicates with a Jolokia HTTP/REST endpoint that exposes the JMX metrics over HTTP/REST/JSON.
Telegraf
Telegraf is a plug-in driven server agent for collecting and sending metrics and events from databases, systems and IoT sensors. In our current monitoring solution, we cannot directly scrape the metrics from Jolokia JMX API through HTTP so we need to include telegraf for scraping the metrics from ActiveMQ. It has the built-in support for ActiveMQ input-plugin and we just need to configure it in the telegraf.conf file. After that, The Prometheus Output Plugin converts metrics into the Prometheus text exposition format and expose them on API by the help of Prometheus Client at <ip-address>:9273/metrics. We can then use this URL of API in our current monitoring solution to display them in Grafana.
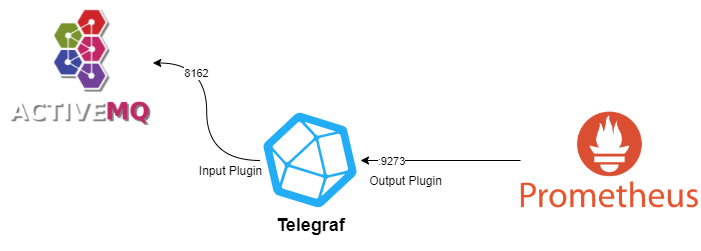
The best thing about this setup is that we don't have to add any utility for scrapping metrics in ActiveMQ as ActiveMQ comes with Jokolia.
ActiveMQ metrics available for monitoring
To get the most out of your deployment of the ActiveMQ Telegraf plugin, consider monitoring some or all of the following metrics:
-
activemq_queues-
Tags:
-
name -
source -
port
-
-
Fields:
-
size -
consumer_count -
enqueue_count -
dequeue_count
-
-
-
activemq_topics-
Tags:
-
name -
source -
port
-
-
Fields:
-
size -
consumer_count -
enqueue_count -
dequeue_count
-
-
-
activemq_subscribers-
Tags:
-
client_id -
subscription_name -
connection_id -
destination_name -
Selector -
active -
source -
port
-
-
Fields:
-
pending_queue_size -
dispatched_queue_size -
dispatched_counter -
enqueue_counter -
dequeue_counter
-
-
Deployment
Telegraf
Telegraf can be deployed on any VM as long as the ActiveMQ Jolokia API is publically accessible. If it is not publically accessible, it should be deployed on the same VM where monitoring solution is deployed.
-
Create a directory named Telegraf and create a file named docker-compose.yml
-
mkdir Telegraf cd Telegraf vi docker-compose.yml
-
Paste the following code inside docker-compose.yml file. Also, change the hostname to the hostname of the VM where it is being deployed.
-
telegraf: image: telegraf restart: always hostname: devops246 ports: - 9273:9273 volumes: - ./telegraf.conf:/etc/telegraf/telegraf.conf:ro
-
Now create a file named,
telegraf.confand paste the following code inside it. -
vi telegraf.conf
-
# Telegraf Configuration # # Telegraf is entirely plugin driven. All metrics are gathered from the # declared inputs, and sent to the declared outputs. # # Plugins must be declared in here to be active. # To deactivate a plugin, comment out the name and any variables. # # Use 'telegraf -config telegraf.conf -test' to see what metrics a config # file would generate. # # Environment variables can be used anywhere in this config file, simply prepend # them with $. For strings the variable must be within quotes (ie, "$STR_VAR"), # for numbers and booleans they should be plain (ie, $INT_VAR, $BOOL_VAR) # Global tags can be specified here in key="value" format. [global_tags] # dc = "us-east-1" # will tag all metrics with dc=us-east-1 # rack = "1a" ## Environment variables can be used as tags, and throughout the config file # user = "$USER" # Configuration for telegraf agent [agent] ## Default data collection interval for all inputs interval = "10s" ## Rounds collection interval to 'interval' ## ie, if interval="10s" then always collect on :00, :10, :20, etc. round_interval = true ## Telegraf will send metrics to outputs in batches of at most ## metric_batch_size metrics. ## This controls the size of writes that Telegraf sends to output plugins. metric_batch_size = 1000 ## For failed writes, telegraf will cache metric_buffer_limit metrics for each ## output, and will flush this buffer on a successful write. Oldest metrics ## are dropped first when this buffer fills. ## This buffer only fills when writes fail to output plugin(s). metric_buffer_limit = 10000 ## Collection jitter is used to jitter the collection by a random amount. ## Each plugin will sleep for a random time within jitter before collecting. ## This can be used to avoid many plugins querying things like sysfs at the ## same time, which can have a measurable effect on the system. collection_jitter = "0s" ## Default flushing interval for all outputs. You shouldn't set this below ## interval. Maximum flush_interval will be flush_interval + flush_jitter flush_interval = "10s" ## Jitter the flush interval by a random amount. This is primarily to avoid ## large write spikes for users running a large number of telegraf instances. ## ie, a jitter of 5s and interval 10s means flushes will happen every 10-15s flush_jitter = "0s" ## By default or when set to "0s", precision will be set to the same ## timestamp order as the collection interval, with the maximum being 1s. ## ie, when interval = "10s", precision will be "1s" ## when interval = "250ms", precision will be "1ms" ## Precision will NOT be used for service inputs. It is up to each individual ## service input to set the timestamp at the appropriate precision. ## Valid time units are "ns", "us" (or "µs"), "ms", "s". precision = "" ## Logging configuration: ## Run telegraf with debug log messages. debug = false ## Run telegraf in quiet mode (error log messages only). quiet = false ## Specify the log file name. The empty string means to log to stderr. logfile = "" ## Override default hostname, if empty use os.Hostname() hostname = "" ## If set to true, do no set the "host" tag in the telegraf agent. omit_hostname = false ############################################################################### # OUTPUT PLUGINS # ############################################################################### [[outputs.prometheus_client]] ## Address to listen on listen = ":9273" path = "/metrics" ## Metric version controls the mapping from Telegraf metrics into ## Prometheus format. When using the prometheus input, use the same value in ## both plugins to ensure metrics are round-tripped without modification. ## ## example: metric_version = 1; ## metric_version = 2; recommended version # metric_version = 1 ## Use HTTP Basic Authentication. # basic_username = "Foo" # basic_password = "Bar" ## If set, the IP Ranges which are allowed to access metrics. ## ex: ip_range = ["192.168.0.0/24", "192.168.1.0/30"] # ip_range = [] ## Expiration interval for each metric. 0 == no expiration # expiration_interval = "60s" ## Collectors to enable, valid entries are "gocollector" and "process". ## If unset, both are enabled. collectors_exclude = ["gocollector", "process"] ## Send string metrics as Prometheus labels. ## Unless set to false all string metrics will be sent as labels. # string_as_label = true ## If set, enable TLS with the given certificate. # tls_cert = "/etc/ssl/telegraf.crt" # tls_key = "/etc/ssl/telegraf.key" ## Set one or more allowed client CA certificate file names to ## enable mutually authenticated TLS connections # tls_allowed_cacerts = ["/etc/telegraf/clientca.pem"] ## Export metric collection time. # export_timestamp = false ############################################################################### # INPUT PLUGINS # ############################################################################### # Description [[inputs.activemq]] ## ActiveMQ WebConsole URL url = "https://192.168.1.217:8162" ## Required ActiveMQ Endpoint ## deprecated in 1.11; use the url option # server = "192.168.50.10" # port = 8161 ## Credentials for basic HTTP authentication username = "admin" password = "admin" ## Required ActiveMQ webadmin root path # webadmin = "admin" ## Maximum time to receive response. # response_timeout = "5s" ## Optional TLS Config # tls_ca = "/etc/telegraf/ca.pem" # tls_cert = "/etc/telegraf/cert.pem" # tls_key = "/etc/telegraf/key.pem" ## Use TLS but skip chain & host verification insecure_skip_verify = true
change the
url = "https://192.168.1.217:8162"in INPUT PLUGINS section to the FQDN or IP of the VM where ACTIVEMQ is running.
-
save this file and run the following command to up the solution
-
docker-compose up -d
Configuration at Prometheus
Now we need to add the prometheus target in our monitoring solution so prometheus can extract those metrics and save it in TSDB. For that go tothe following directory and edit the prometheus.yml and then add this snippet.
cd prometheus/prometheus
vi prometheus.yml
- job_name: 'activemq'
scrape_interval: 5m
# scheme : https
metrics_path: /metrics
static_configs:
- targets: ['devops246.ef.com:9273']
# tls_config:
# insecure_skip_verify: true
Please change the targets ip/FQDN (devops246.ef.com) to the IP where Telegraf has been deployed. Also uncomment the scheme, tls_config, insecure_skip_verify if using https.
Save this file and exit. Now restart the prometheus with the following command:
docker-compose restart prometheus
That's it. Now we just need to import the Grafana dashboard.